This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Hosted at one of Mindspace’s coworking locations, the event was a convergence of insightful talks and professional networking. Mindspace , a global coworking and flexible office provider with over 45 locations worldwide, including 13 in Germany, offered a conducive environment for this knowledge-sharing event.
The goal of digital transformation remains the same as ever – to become more data-driven. We have learned how to gain a competitive advantage by capturing business events in data. Events are data snap-shots of complex activity sourced from the web, customer systems, ERP transactions, social media, […].
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
So let’s do a quick overview of the job of data engineer, and maybe you might find a new interest. Building and maintaining datapipelinesData integration is the process of combining data from multiple sources into a single, consistent view. Think of data engineers as the architects of the data ecosystem.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
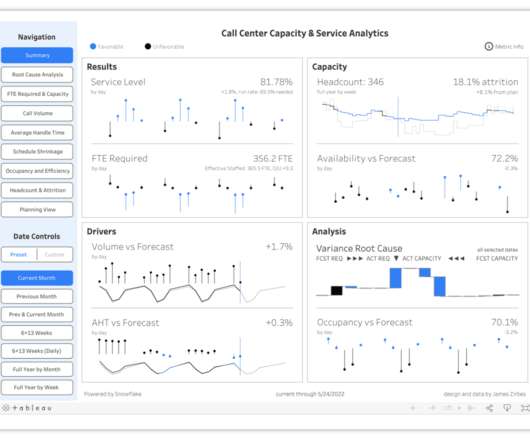
More and more businesses are looking to better leverage their outsourced call center data to make more data-driven decisions. To do this on your own, you would need to create a datawarehouse, optimize the reporting performance, and very clearly visualize the data. Another way to think of it is as Data Activation.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity. from 2025 to 2030.
People were familiar with the value of a data catalog (and the growing need for data governance ), though many admitted to being somewhat behind on their journeys. In this blog, I’ll share a quick high-level overview of the event, with an eye to core themes. In “The modern data stack is dead, long live the modern data stack!”
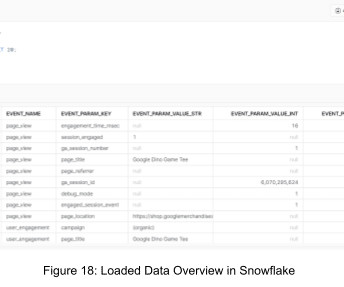
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw eventdata from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time. Each platform offers unique features and benefits, making it vital for data engineers to understand their differences.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
Must Read Blogs: Exploring the Power of DataWarehouse Functionality. Data Lakes Vs. DataWarehouse: Its significance and relevance in the data world. Exploring Differences: Database vs DataWarehouse. It is commonly used in datawarehouses for business analytics and reporting.
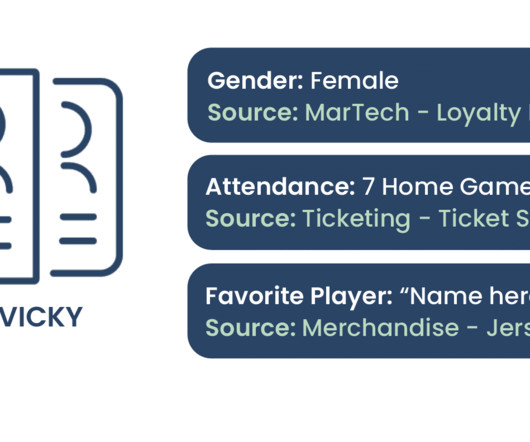
We are going to break down what we know about Victory Vicky based on all the data sources we have moved into our datawarehouse. The loyalty program is located in the MarTech Stack and moves data effortlessly into the datawarehouse. This information is also funneled into the datawarehouse.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
These systems represent data as knowledge graphs and implement graph traversal algorithms to help find content in massive datasets. These systems are not only useful for a wide range of industries, they are fun for data engineers to work on. Interested in attending an ODSC event? Learn more about our upcoming events here.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Interested in attending an ODSC event?
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of datapipelines. Provenance Repository : This repository records all provenance events related to FlowFiles.
Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources. Whether it’s a cloud datawarehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs.
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. Announcing the ODSC East 2024 Complete Schedule Check out this article for a full rundown of what you can expect from the ODSC East 2024 schedule, including keynotes, bootcamp sessions, extra events, and more.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular cloud datawarehouses like Snowflake can provide the scalability needed as your business grows.
The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. It even offers a user-friendly interface to visualize the pipelines and monitor progress. The Data Source Tool can automate scanning DDL and profiling tables between source and target, comparing them, and then reporting findings.
It’s common to have terabytes of data in most datawarehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. To assign the DMF to the table, we must first add a data metric schedule to the table CUSTOMERS.
Other features include email notifications (to let you know if a job failed or is running long), job scheduling, orchestration to ensure your data gets to Snowflake when you want it, and of course, full automation of your complete data ingestion process.
Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization: Locate and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
The most common example of such databases is where events are tracked. For software products or ERP backend databases, thousands of data units must be tracked and monitored. Speed: The agent on the source database will filter the data before sending it through the datapipeline.
Datapipeline orchestration. Moving/integrating data in the cloud/data exploration and quality assessment. Supports the ability to interact with the actual data and perform analysis on it. This provides the facility a time or event for a job to run and offers useful post-run information. Scheduling.
Data Quality Dimensions Data quality dimensions are the criteria that are used to evaluate and measure the quality of data. These include the following: Accuracy indicates how correctly data reflects the real-world entities or events it represents. It is SQL-based and integrates well with modern datawarehouses.
ETL usually stands for “Extract, Transform and Load,” and it refers to a process in data warehousing. Sourcing the data In our case, the data was provided by our client, which was a product-based organization. The datapipelines can be scheduled as event-driven or be run at specific intervals the users choose.
This strategic replication ensures that even if an issue arises in one area, your data remains accessible from another, creating a safety net for your critical information. In the face of unexpected events or outages, Snowflake introduces failover mechanisms.
The platform’s integration with Azure services ensures a scalable and secure environment for Data Science projects. Azure Synapse Analytics Previously known as Azure SQL DataWarehouse , Azure Synapse Analytics offers a limitless analytics service that combines big data and data warehousing.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. The default value is 360 seconds. If not, it will retry after a certain duration (E.g., 30 minutes).
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data. In that sense, data modernization is synonymous with cloud migration. Access the resources your data applications need — no more, no less.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content