This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A SageMaker domain. A QuickSight account (optional).
Introduction The demand for data to feed machinelearning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […]. The post Building an ETL DataPipeline Using Azure Data Factory appeared first on Analytics Vidhya.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. The movement of data in a pipeline from one point to another.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL datapipeline in ML? Let’s look at the importance of ETL pipelines in detail.
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
These procedures are central to effective data management and crucial for deploying machinelearning models and making data-driven decisions. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline. What is a DataPipeline?
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machinelearning models and develop artificial intelligence (AI) applications.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machinelearning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. This tool automatically detects problems in an ML dataset. You can watch it on demand here.
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
So let’s do a quick overview of the job of data engineer, and maybe you might find a new interest. Building and maintaining datapipelinesData integration is the process of combining data from multiple sources into a single, consistent view. Think of data engineers as the architects of the data ecosystem.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machinelearning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and datawarehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). It can be used with both on-premise and multi-cloud environments.
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
This is a perfect use case for machinelearning algorithms that predict metrics such as sales and product demand based on historical and environmental factors. Cleaning and preparing the data Raw data typically shouldn’t be used in machinelearning models as it’ll throw off the prediction.
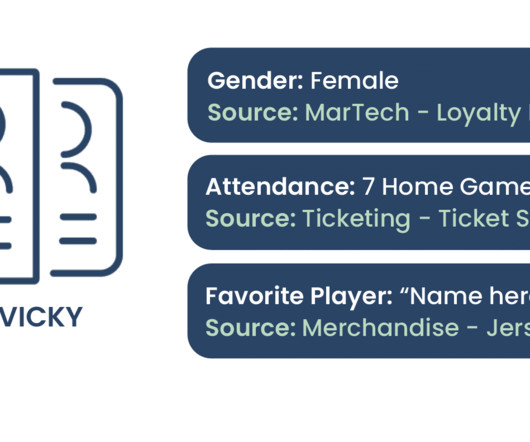
We are going to break down what we know about Victory Vicky based on all the data sources we have moved into our datawarehouse. The loyalty program is located in the MarTech Stack and moves data effortlessly into the datawarehouse. This information is also funneled into the datawarehouse.
On-Premises to The Cloud This type of migration involves moving an organization’s BI platform from an on-premises environment (such as a local server or data center) to a cloud-based environment. Read about phData’s Tableau Cloud Migration offerings.
Data versioning control is an important concept in machinelearning, as it allows for the tracking and management of changes to data over time. As data is the foundation of any machinelearning project, it is essential to have a system in place for tracking and managing changes to data over time.
As businesses increasingly turn to cloud solutions, Azure stands out as a leading platform for Data Science, offering powerful tools and services for advanced analytics and MachineLearning. This roadmap aims to guide aspiring Azure Data Scientists through the essential steps to build a successful career.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. If you’re looking to leverage the full power of the Snowflake Data Cloud, let phData be your guide.
Our partnership with Snorkel AI can help make scalable data science on Snowflake more accessible across an organization to help drive business outcomes. But – the value of rich textual data centralized within Snowflake can’t be realized by training machinelearning models until this raw data is curated and labeled.
Our partnership with Snorkel AI can help make scalable data science on Snowflake more accessible across an organization to help drive business outcomes. But – the value of rich textual data centralized within Snowflake can’t be realized by training machinelearning models until this raw data is curated and labeled.
This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time. Its open-source nature means it’s continually evolving, thanks to contributions from its user community.
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. Discover the critical role of workflow orchestration in bridging Generative AI with classical MachineLearning for robust, production-ready systems.
It is a data integration process that involves extracting data from various sources, transforming it into a suitable format, and loading it into a target system, typically a datawarehouse. ETL is the backbone of effective data management, ensuring organisations can leverage their data for informed decision-making.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content