This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift datawarehouse.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. Solution overview The following diagram illustrates the solution architecture for each option.
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines. Dataiku and Snowflake: A Good Combo?
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. When needed, the system can access an ODAP datawarehouse to retrieve additional information.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst. You can watch it on demand here.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an MLpipeline?
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). ” Are foundation models trustworthy?
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Datapipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
In addition, MLOps practices like building data, experting tracking, versioning, artifacts and others, also need to be part of the GenAI productization process. For example, when indexing a new version of a document, it’s important to take care of versioning in the MLpipeline. This helps cleanse the data.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. IBM watsonx.ai
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Why Migrate to a Modern Data Stack? With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. Data teams can focus on delivering higher-value data tasks with better organizational visibility.
Data fabric Data fabric architectures are designed to connect data platforms with the applications where users interact with information for simplified data access in an organization and self-service data consumption. Then, it applies these insights to automate and orchestrate the data lifecycle.
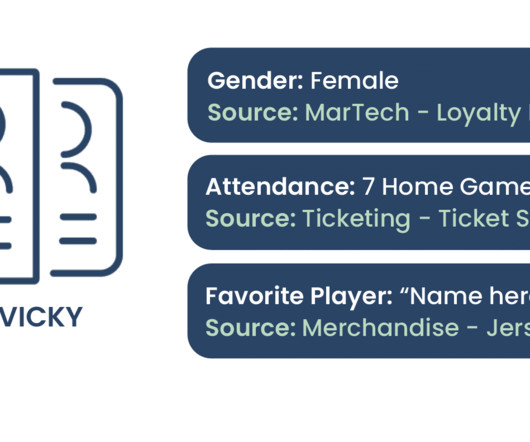
We are going to break down what we know about Victory Vicky based on all the data sources we have moved into our datawarehouse. The loyalty program is located in the MarTech Stack and moves data effortlessly into the datawarehouse. This information is also funneled into the datawarehouse.
And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used. Scheduling.
Powering a knowledge management system with a data lakehouse Organizations need a data lakehouse to target data challenges that come with deploying an AI-powered knowledge management system. It provides the combination of data lake flexibility and datawarehouse performance to help to scale AI.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. This includes data quality, privacy, and compliance.
Faced with these challenges, asset servicers have acquired numerous technologies over time to meet their risk management, fund analytics, and settlement needs, leading to data fragmentation and inheriting complex data flows. Data movements lead to high costs of ETL and rising data management TCO.
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data. In that sense, data modernization is synonymous with cloud migration. Access the resources your data applications need — no more, no less.
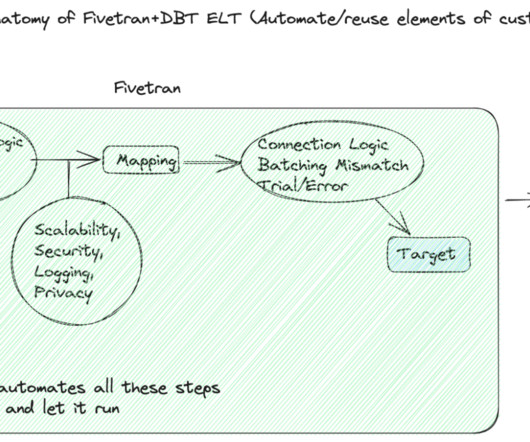
Fivetran also takes care of all the manual elements of building and maintaining a datapipeline that is not business-related so that data teams don’t have to. With dbt, transforming the data according to business logic becomes easy. This is where dbt comes in – powering the transformations.
As companies increasingly rely on data for decision-making, poor-quality data can lead to disastrous outcomes. Even the most sophisticated ML models, neural networks, or large language models require high-quality data to learn meaningful patterns. When bad data is inputted, it inevitably leads to poor outcomes.
It uses metadata and data management tools to organize all data assets within your organization. It synthesizes the information across your data ecosystem—from data lakes, datawarehouses, and other data repositories—to empower authorized users to search for and access business-ready data for their projects and initiatives.
In case of complex datapipelines, a combination of Materialized Views, Stored Procedures, and Scheduled Queries could be a better choice than to solely rely on Scheduled Queries by itself. This allows you to use tools like BigQuery to query the data before it’s migrated to a native BigQuery table.
I have checked the AWS S3 bucket and Snowflake tables for a couple of days and the Datapipeline is working as expected. The scope of this article is quite big, we will exercise the core steps of data science, let's get started… Project Layout Here are the high-level steps for this project.
Organizations run millions of Apache Spark applications each month to prepare, move, and process their data for analytics and machine learning (ML). During development, data engineers often spend hours sifting through log files, analyzing execution plans, and making configuration changes to resolve issues.
In “The modern data stack is dead, long live the modern data stack!” the presenters elaborated on the common pain points of the cloud datawarehouse today and predicted what it may look like in the future. So, how can a data catalog support the critical project of building datapipelines?
Both persistent staging and data lakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer datapipeline. It’s not just a dumping ground for data, but a crucial step in your customer data processing workflow.
Artificial intelligence (AI) and machine learning (ML) are transforming businesses at an unprecedented pace. And yet, many data leaders struggle to trust their AI-driven insights due to poor data observability. If youre a data leader grappling with trust, transparency, and governance in AI datapipelines, youre not alone.
Datapipelines must seamlessly integrate new data at scale. Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources. You can build and manage an incremental datapipeline to update embeddings on Vectorstore at scale.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content