This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, Reveal experts showcase how they used Amazon Comprehend in their document processingpipeline to detect and redact individual pieces of PII. Amazon Comprehend is a fully managed and continuously trained naturallanguageprocessing (NLP) service that can extract insight about the content of a document or text.
Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
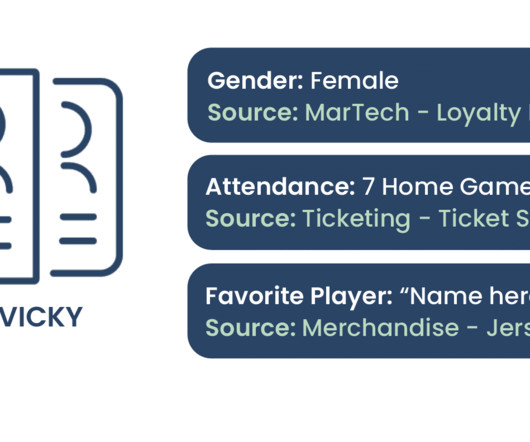
We are going to break down what we know about Victory Vicky based on all the data sources we have moved into our datawarehouse. The loyalty program is located in the MarTech Stack and moves data effortlessly into the datawarehouse. This information is also funneled into the datawarehouse.
This technological shift placed computing power into the hands of the individual consumer — yet access to corporate data still resided with the “techies”. The Rise of the DataWarehouse. The birth of the enterprise datawarehouse was heralded as the solution to limited access.
It uses metadata and data management tools to organize all data assets within your organization. It synthesizes the information across your data ecosystem—from data lakes, datawarehouses, and other data repositories—to empower authorized users to search for and access business-ready data for their projects and initiatives.
The platform’s integration with Azure services ensures a scalable and secure environment for Data Science projects. Azure Synapse Analytics Previously known as Azure SQL DataWarehouse , Azure Synapse Analytics offers a limitless analytics service that combines big data and data warehousing.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content