This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
It involves retrieving data from various sources, such as databases, spreadsheets, or even cloud storage. The goal is to collect relevant data without affecting the source system’s performance. Compatibility with Existing Systems and Data Sources Compatibility is critical. How to drop a database in SQL server?
Jinja’s usage will significantly empower you to build dynamic and reusable datapipelines , especially when dealing with conditional logic and templatization within dbt. Conclusion Jinja offers a dynamic toolkit that enhances your dbt models and elevates our data-wrangling skills. What is Jinja?
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wrangling processes with a fast and seamless user experience to manage and access data products.
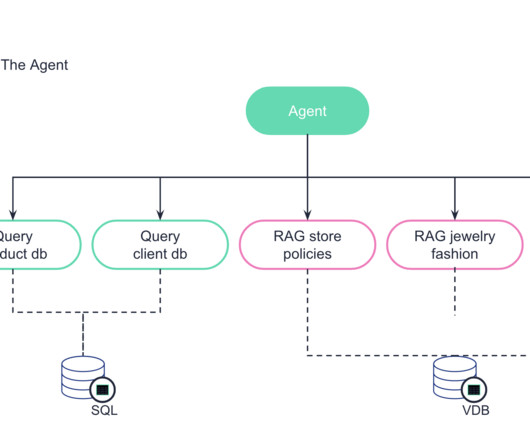
Capabilities include session loading, query refinement, history saving, guardrails like subject classification and a toxicity filter, connection to monitoring, the ability to iterate and retrain the model, external database connections, and more. They also had access to a database with client data and a database with product data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content