This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
The needs and requirements of a company determine what happens to data, and those actions can range from extraction or loading tasks […]. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL. The post Interacting with Remote Databases – PostgreSQL and DBAPIs appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. The post ETL Pipeline using Shell Scripting | DataPipeline appeared first on Analytics Vidhya. What is shell scripting? For Unix-like operating systems, a shell is a […].
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Handling and processing the streaming data is the hardest work for Data Analysis. We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined DataPipeline appeared first on Analytics Vidhya.
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating datapipelines, and efficiently managing data warehouses.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
Accurate and secure data can help to streamline software engineering processes and lead to the creation of more powerful AI tools, but it has become a challenge to maintain the quality of the expansive volumes of data needed by the most advanced AI models. Featured image credit: Shubham Dhage/Unsplash
Datapipelines have been crucial for brands in a number of ways. In March, Hubspot talked about the shift towards incorporating big data into marketing pipelines in B2B campaigns. “A However, it is important to use the right datapipelines to leverage these benefits.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build datapipelines to move data from Amazon Aurora to Amazon Redshift.
A data engineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless datapipelines. While data scientists and analysts receive […] The post What Data Engineers Really Do? appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Our previous articles discussed Spark databases, installation, and working of Spark in Python. The post Machine learning Pipeline in Pyspark appeared first on Analytics Vidhya. Introduction In this article, we will learn about machine learning using Spark.
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse. Database size limits of 10GB.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
A data fabric is textured approach to combining disparate data sources, datapipelines, databases, data streams and cloud data services into one woven unified entity.
This can be useful for data scientists who need to streamline their data science pipeline or automate repetitive tasks. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and data analysis.
What businesses need from cloud computing is the power to work on their data without having to transport it around between different clouds, different databases and different repositories, different integrations to third-party applications, different datapipelines and different compute engines.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
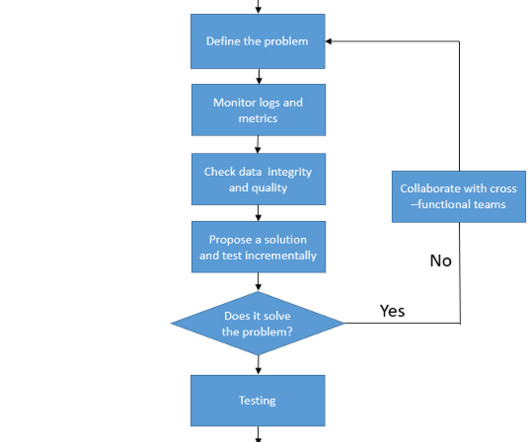
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
With the help of the insights, we make further decisions on how to experiment and optimize the data for further application of algorithms for developing prediction or forecast models. What are ETL and datapipelines? These datapipelines are built by data engineers. E.g., join() and split() methods.
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
One of the key elements that builds a data fabric architecture is to weave integrated data from many different sources, transform and enrich data, and deliver it to downstream data consumers. As a part of datapipeline, Address Verification Interface (AVI) can remediate bad address data.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine.
In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms. We will also discuss the difference between imperative and declarative database change management approaches. These environments house the database and schema objects required for both governed and non-governed instances.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Summary: Time series databases (TSDBs) are built for efficiently storing and analyzing data that changes over time. This data, often from sensors or IoT devices, is typically collected at regular intervals. Buckle up as we navigate the intricacies of storing and analysing this dynamic data.
This orchestration process encompasses interactions with external APIs, retrieval of contextual data from vector databases, and maintaining memory across multiple LLM calls. This makes it easy to connect your datapipeline to the data sources that you need.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content