This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
Type of Data: structured and unstructured from different sources of data Purpose: Cost-efficient big data storage Users: Engineers and scientists Tasks: storing data as well as big data analytics, such as real-time analytics and deeplearning Sizes: Store data which might be utilized.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a data engineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists.
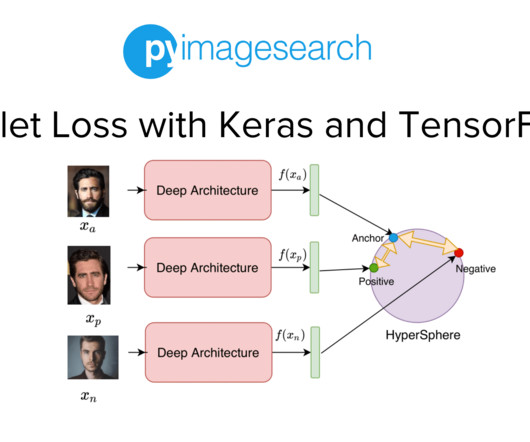
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively. Dolt Dolt is an open-source relational database system built on Git. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
Machine learning The 6 key trends you need to know in 2021 ? Automation Automating datapipelines and models ➡️ 6. First, let’s explore the key attributes of each role: The Data Scientist Data scientists have a wealth of practical expertise building AI systems for a range of applications.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. That’s not the case.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. Therefore, BMW established a centralized ML/deeplearning infrastructure on premises several years ago and continuously upgraded it.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
Implementing Face Recognition and Verification Given that we want to identify people with id-1021 to id-1024 , we are given 1 image (or a few samples) of each person, which allows us to add the person to our face recognition database. Then, whichever feature has the minimum distance with our test feature is the identity of the test image.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Check out the AWS Blog for more practices about building ML features from a modern data warehouse.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.”
To solve this problem, we had to design a strong datapipeline to create the ML features from the raw data and MLOps. Multiple data sources ODIN is an MMORPG where the game players interact with each other, and there are various events such as level-up, item purchase, and gold (game money) hunting.
The second is to provide a directed acyclic graph (DAG) for datapipelining and model building. If you use the filesystem as an intermediate data store, you can easily DAG-ify your data cleaning, feature extraction, model training, and evaluation. Teams that primarily access hosted data or assets (e.g.,
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. mp4,webm, etc.), and audio files (.wav,mp3,acc,
A feature store is a data platform that supports the creation and use of feature data throughout the lifecycle of an ML model, from creating features that can be reused across many models to model training to model inference (making predictions). It can also transform incoming data on the fly.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deeplearning models that are pre-trained with attention mechanisms on massive datasets. This helps cleanse the data.
Project Structure Creating Adversarial Examples Robustness Toward Adversarial Examples Summary Citation Information Adversarial Learning with Keras and TensorFlow (Part 1): Overview of Adversarial Learning In this tutorial, you will learn about adversarial examples and how they affect the reliability of neural network-based computer vision systems.
At the heart of this technological revolution are Large Language Models (LLMs), deeplearning models capable of understanding and generating text remarkably smoothly and accurately. Let’s take a look at how LLMs can be used to generate high-quality synthetic tabular data from a real dataset or not.
Thirdly, the presence of GPUs enabled the labeled data to be processed. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed.
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Python : Great for including AI in Python-based software or datapipelines.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. This allows you to control which IAM principals are allowed to decrypt the data and view it. Choose Create data source.
Tools range from data platforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. Data and workflow orchestration: Ensuring efficient datapipeline management and scalable workflows for LLM performance.
You can use Amazon Kendra to quickly build high-accuracy generative AI applications on enterprise data and source the most relevant content and documents to maximize the quality of your Retrieval Augmented Generation (RAG) payload, yielding better large language model (LLM) responses than using conventional or keyword-based search solutions.
MLflow is language- and framework-agnostic, and it offers convenient integration with the most popular machine learning and deeplearning frameworks. MLflow offers automatic logging for the most popular machine learning and deeplearning libraries. It also has APIs for R and Java, and it supports REST APIs.
Datapipeline orchestration. Moving/integrating data in the cloud/data exploration and quality assessment. Organizations launched initiatives to be “ data-driven ” (though we at Hired Brains Research prefer the term “data-aware”). On-premises business intelligence and databases.
This section explores popular software and frameworks for Data Analysis and modelling is designed to cater to the diverse needs of Data Scientists: Azure Data Factory This cloud-based data integration service enables the creation of data-driven workflows for orchestrating and automating data movement and transformation.
As computational power increased and data became more abundant, AI evolved to encompass machine learning and data analytics. This close relationship allowed AI to leverage vast amounts of data to develop more sophisticated models, giving rise to deeplearning techniques.
It also can minimize the risks of miscommunication in the process since the analyst and customer can align on the prototype before proceeding to the build phase Design: DALL-E, another deeplearning model developed by OpenAI to generate digital images from natural language descriptions, can contribute to the design of applications.
By understanding the role of each tool within the MLOps ecosystem, you'll be better equipped to design and deploy robust ML pipelines that drive business impact and foster innovation. TensorFlow TensorFlow is a popular machine learning framework developed by Google that offers the implementation of a wide range of neural network models.
Roadmap to Harnessing ML for Climate Change Mitigation The journey to harnessing the full potential of ML for climate change mitigation begins with laying a solid foundation for data infrastructure and integration. We're committed to supporting and inspiring developers and engineers from all walks of life.
Step 2: Data Gathering Collect relevant historical data that will be used for forecasting. This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., databases, APIs, CSV files).
The job reads features, generates predictions, and writes them to a database. The client queries and reads the predictions from the database when needed. Monitoring component Implementing effective monitoring is key to successfully operating machine learning projects. An ML batch job runs periodically to perform inference.
Other good-quality datasets that aren’t currently FHIR but can be easily converted include Centers for Medicare & Medicaid Services (CMS) Public Use Files (PUF) and eICU Collaborative Research Database from MIT (Massachusetts Institute of Technology). He has worked with multiple federal agencies to advance their data and AI goals.
The exploration of common machine learningpipeline architecture and patterns starts with a pattern found in not just machine learning systems but also database systems, streaming platforms, web applications, and modern computing infrastructure. Single leader architecture What is single leader architecture?
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. This new data from outside of the LLM’s original training data set is called external data. The data might exist in various formats such as files, database records, or long-form text.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content