Relational Graph Transformers
Hacker News
APRIL 28, 2025
Relational Graph Transformers represent the next evolution in Relational Deep Learning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.
 Data Pipeline Database Deep Learning
Data Pipeline Database Deep Learning 
Hacker News
APRIL 28, 2025
Relational Graph Transformers represent the next evolution in Relational Deep Learning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.

insideBIGDATA
JUNE 4, 2024
Modern data pipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Machine Learning Blog
OCTOBER 23, 2024
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.

Smart Data Collective
SEPTEMBER 23, 2020
Type of Data: structured and unstructured from different sources of data Purpose: Cost-efficient big data storage Users: Engineers and scientists Tasks: storing data as well as big data analytics, such as real-time analytics and deep learning Sizes: Store data which might be utilized.

Heartbeat
NOVEMBER 6, 2023
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex data pipelines.

Smart Data Collective
JUNE 10, 2022
In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a data engineer, you could also build and maintain data pipelines that create an interconnected data ecosystem that makes information available to data scientists.

FEBRUARY 13, 2023
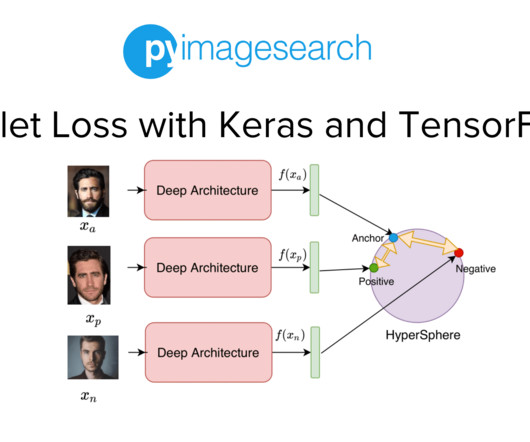
Project Structure Creating Our Configuration File Creating Our Data Pipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py

Expert insights. Personalized for you.






































Let's personalize your content