This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The following demo shows Agent Creator in action. Chunker Snap – Segments large texts into manageable pieces.
Database name : Enter dev. Database user : Enter awsuser. SageMaker Canvas integration with Amazon Redshift provides a unified environment for building and deploying machine learning models, allowing you to focus on creating value with your data rather than focusing on the technical details of building datapipelines or ML algorithms.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
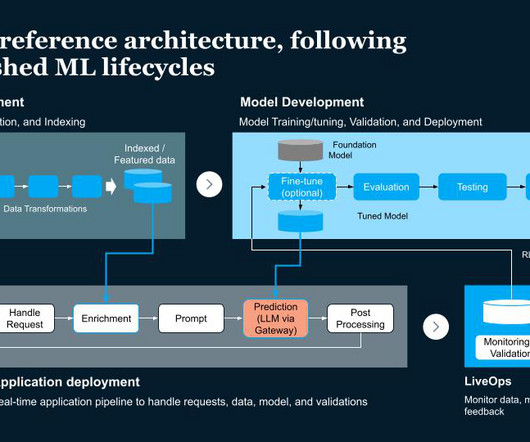
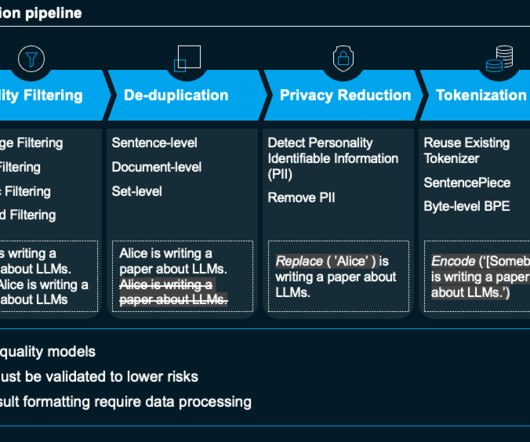
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. On the Import data page, for Data Source , choose DocumentDB and Add Connection. Finally, select your read preference.
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications. In the end, we’ll provide resources on how to get started.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Enter a stack name, such as Demo-Redshift. yaml locally.
” – James Tu, Research Scientist at Waabi Play with this project live For more: Dive into documentation Get in touch if you’d like to go through a custom demo with your team Comet ML Comet ML is a cloud-based experiment tracking and optimization platform. Dolt Dolt is an open-source relational database system built on Git.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably. Systems can be dynamic.
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
Demo: How to Build a Smart GenAI Call Center App How we used LLMs to turn call center conversation audio files of customers and agents into valuable data in a single workflow orchestrated by MLRun. The datapipeline - Takes the data from different sources (document, databases, online, data warehouses, etc.),
For enterprises, the value-add of applications built on top of large language models is realized when domain knowledge from internal databases and documents is incorporated to enhance a model’s ability to answer questions, generate content, and any other intended use cases.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. This is where the content for the demo solution will be stored. For the demo solution, choose the default ( Claude V3 Sonnet ). For the hotel-bot demo, try the default of 4. Do not specify an S3 prefix.
Tuesday is the first day of the AI Expo and Demo Hall , where you can connect with our conference partners and check out the latest developments and research from leading tech companies. Finally, get ready for some All Hallows Eve fun with Halloween Data After Dark , featuring a costume contest, candy, and more. What’s next?
This functionality eliminates the need for manual schema adjustments, streamlining the data ingestion process and ensuring quicker access to data for their consumers. As you can see in the above demo, it is incredibly simple to use INFER_SCHEMA and SCHEMA EVOLUTION features to speed up data ingestion into Snowflake.
Data producers and consumers alike are working from home and hybrid locations more often. And in an increasingly remote workforce, people need to access data systems easily to do their jobs. This might mean that they’re accessing a database from a smartphone, computer, or tablet. Today, data dwells everywhere.
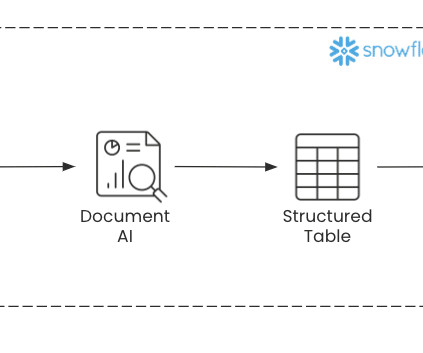
Snowflake Solution In the past, companies would hire employees whose focus was scanning, entering, and correcting data from documents into an organized table or database. Before we dive into the demo, the next section covers a couple of the key technologies that enable Document AI. That’s where Document AI comes in!
Operational Risks identify operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization identify and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
Building MLOpsPedia This demo on Github shows how to fine tune an LLM domain expert and build an ML application Read More Building Gen AI for Production The ability to successfully scale and drive adoption of a generative AI application requires a comprehensive enterprise approach. Let’s dive into the data management pipeline.
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. conda activate snowflake-demo ). Validating the Deployment in Snowflake Existence – The newly created Python UDF should be present under the Analytics schema under the HOL_DB database.
For a short demo on Snowpark, be sure to check out the video below. Utilizing Streamlit as a Front-End At this point, we have all of our data processing, model training, inference, and model evaluation steps set up with Snowpark. that were previously all needed to put your app into production.
This is commonly handled in code that pulls data from databases, but you can also do this within the SQL query itself. If you’re interested in learning more about our Toolkit or getting a demo around the functionality and how it could help your organization, give us a shout !
Finally, Week 4 ties it all together, guiding participants through the practical builder demos from cloning compound AI architectures to building production-ready applications. These hands-on demo workshops and live demonstrations show attendees how to use cutting-edge tools to create impactful AI applications in real-time.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Let’s go and talk about machine learning pipelining.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Let’s go and talk about machine learning pipelining.
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do data analysis BI report generation/data analysis In BI/data analysis world, people usually need to query data (small/large).
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably. Systems can be dynamic.
Vector Database : A vector database is a specialized database designed to efficiently store, manage, and retrieve high-dimensional vectors, also known as vector embeddings. Vector databases support similarity search operations, allowing users to find vectors most similar to a given query vector.
An ML platform standardizes the technology stack for your data team around best practices to reduce incidental complexities with machine learning and better enable teams across projects and workflows. We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Why are you building an ML platform?
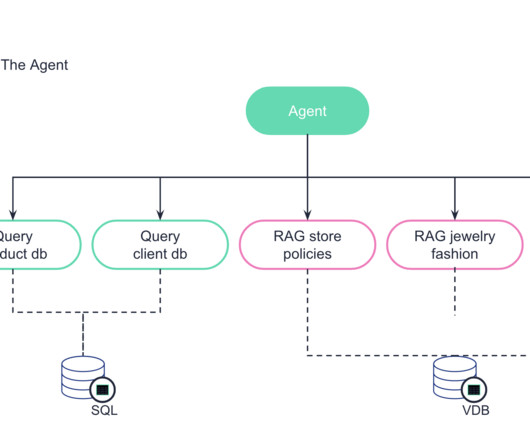
In this blog post, we provide a staged approach for rolling out gen AI, together with use cases, a demo and examples that you can implement and follow. Demo: IguaJewels Now let’s see such a gen AI chatbot in action. They also had access to a database with client data and a database with product data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content