This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse. Database size limits of 10GB.
With Code Interpreter, you can perform tasks such as data analysis, visualization, coding, math, and more. You can also upload and download files to and from ChatGPT with this feature. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and data analysis.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Database name : Enter dev. Database user : Enter awsuser. You can now view the predictions and download them as CSV. You can also generate single predictions for one row of data at a time. You can reference the preceding screen shot for Nested Stack , where you will find the cluster identifier output.
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Download the free, unabridged version here. Automation Automating datapipelines and models ➡️ 6.
In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms. We will also discuss the difference between imperative and declarative database change management approaches. These environments house the database and schema objects required for both governed and non-governed instances.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or data warehouse. If it’s not done right away, then later.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a user name, password, and database name. For this post, we add our restaurant data. Choose Add connection.
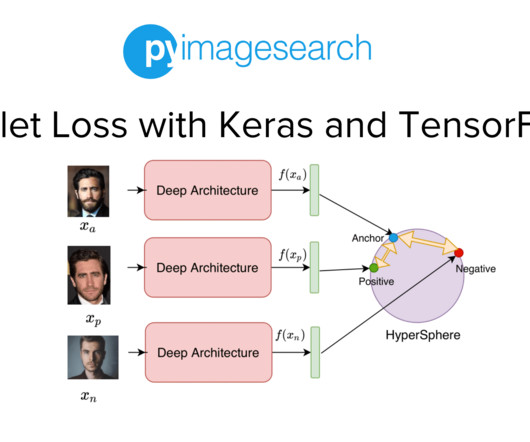
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The crop_faces.py
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss.
Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time. This can prevent lengthy datadownloads to the local disks before initiating their mode training.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively. Dolt Dolt is an open-source relational database system built on Git. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
Implementing Face Recognition and Verification Given that we want to identify people with id-1021 to id-1024 , we are given 1 image (or a few samples) of each person, which allows us to add the person to our face recognition database. On Lines 40 and 41 , we define the path to our face database (i.e.,
A feature store is a data platform that supports the creation and use of feature data throughout the lifecycle of an ML model, from creating features that can be reused across many models to model training to model inference (making predictions). It can also transform incoming data on the fly.
When you think of the lifecycle of your data processes, Alteryx and Snowflake play different roles in a data stack. Alteryx provides the low-code intuitive user experience to build and automate datapipelines and analytics engineering transformation, while Snowflake can be part of the source or target data, depending on the situation.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. First of all, machine learning engineers and data scientists often use data from different data vendors.
Read our eBook TDWI Checklist Report: Best Practices for Data Integrity in Financial Services To learn more about driving meaningful transformation in the financial service industry, download our free ebook. That creates new challenges in data management and analytics. Real-time data is the goal.
For enterprises, the value-add of applications built on top of large language models is realized when domain knowledge from internal databases and documents is incorporated to enhance a model’s ability to answer questions, generate content, and any other intended use cases.
What is Apache Kafka, and How is it Used in Building Real-time DataPipelines? It is capable of handling high-volume and high-velocity data. Start by downloading the Snowflake Kafka Connector. If unable to find it, look in the docker-desktop-data. Apache Kafka is an open-source event distribution platform.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Some industries rely not only on traditional data but also need data from sources such as security logs, IoT sensors, and web applications to provide the best customer experience. For example, before any video streaming services, users had to wait for videos or audio to get downloaded. Happy Learning!
Fortunately, Fivetran’s new Hybrid Architecture addresses this security need and now these organizations (and others) can get the best of both worlds: a managed platform and pipelines processed in their own environment. What is the Hybrid Deployment Model? How Does the Hybrid Model Work?
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. Validating the Deployment in Snowflake Existence – The newly created Python UDF should be present under the Analytics schema under the HOL_DB database.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Schema refers to the way data is organized or defined within a database.
The Snowflake account is set up with a demo database and schema to load data. Sample CSV files (download files here ) Step 1: Load Sample CSV Files Into the Internal Stage Location Open the SQL worksheet and create a stage if it doesn’t exist. This is incredibly useful for both Data Engineers and Data Scientists.
Top Use Cases of Snowpark With Snowpark, bringing business logic to data in the cloud couldn’t be easier. Transitioning work to Snowpark allows for faster ML deployment, easier scaling, and robust datapipeline development. ML Applications For data scientists, models can be developed in Python with common machine learning tools.
We will understand the dataset and the datapipeline for our application and discuss the salient features of the NSL framework in detail. Finally, in the 4th part of the tutorial series, we will look at our application’s training and inference pipeline and implement these routines using the Keras and TensorFlow libraries.
Just click this button and fill out the form to download it. Having gone public in 2020 with the largest tech IPO in history, Snowflake continues to grow rapidly as organizations move to the cloud for their data warehousing needs. Importing data allows you to ingest a copy of the source data into an in-memory database.
I have checked the AWS S3 bucket and Snowflake tables for a couple of days and the Datapipeline is working as expected. The scope of this article is quite big, we will exercise the core steps of data science, let's get started… Project Layout Here are the high-level steps for this project.
Two Data Scientists: Responsible for setting up the ML models training and experimentation pipelines. One Data Engineer: Cloud database integration with our cloud expert. Sourcing the data In our case, the data was provided by our client, which was a product-based organization. Redshift, S3, and so on.
What is Semi-structured Data? Semi-structured data, also called partially structured data, is a form that does not adhere to the conventional tabular structure found in relational databases or other data tables. Semi-structured data can come from many sources, including applications, sensors, and mobile devices.
Vector Database : A vector database is a specialized database designed to efficiently store, manage, and retrieve high-dimensional vectors, also known as vector embeddings. Vector databases support similarity search operations, allowing users to find vectors most similar to a given query vector.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. Jython is to be used for database connectivity only. The default value is Python3.
Its sales analysts face a daily challenge: they need to make data-driven decisions but are overwhelmed by the volume of available information. They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels.
Here are five data quality best practices which business leaders should focus. Think holistically: Address the entire datapipelineData quality should not simply be focused on finding and fixing existing problems within static data. Waiting until later risks sending a bogus “lead” to inside sales for follow up.
First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse. Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analytical data processing and storage capabilities within a cloud-based infrastructure.
This new data from outside of the LLM’s original training data set is called external data. The data might exist in various formats such as files, database records, or long-form text. Datapipelines must seamlessly integrate new data at scale. These indexes continuously accumulate documents.
Yet despite these rich capabilities, challenges stillarise The Fragmentation Challenge With so many modular open-source libraries and frameworks now available, effectively stitching together coherent data science application workflows poses a frequent headache for practitioners. This communal ethos ultimately empowers grassroots innovation.
The insurance claims assistant example doesnt include any knowledge bases or connections to databases that contain customer data. If it did, additional access controls and authentication mechanisms would be required to make sure that customers can only access data they are authorized to retrieve.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content