This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
How to consume a Linked DataEvent Stream and store it in a TimescaleDB database Photo by Scott Graham on Unsplash Linked dataevent stream Linked DataEvent Streams represent and share fast and slow-moving data on the Web using the Resource Description Framework (RDF). and PostgreSQL 14.4
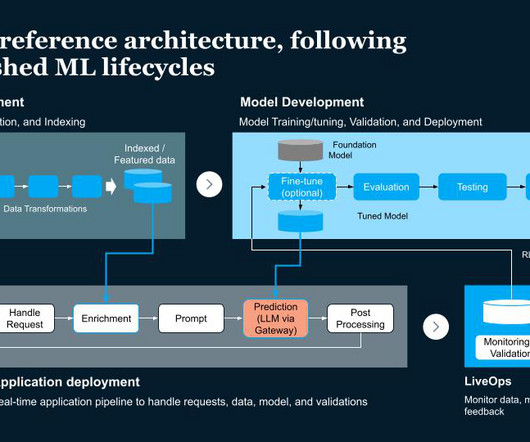
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to.
Summary: Time series databases (TSDBs) are built for efficiently storing and analyzing data that changes over time. This data, often from sensors or IoT devices, is typically collected at regular intervals. Within this data ocean, a specific type holds immense value: time series data.
Brian Chesky, CEO of Airbnb, spoke at a Y Combinator event this summer. (Y Neum AI Photo) Co-founders: David de Matheu and Pinhas Kevin Cohen Explain what your startup does in two sentences: Neum AI is the next generation of datapipelines built specifically for retrieval augmented generation (RAG).
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
In this post we highlight how the AWS Generative AI Innovation Center collaborated with the AWS Professional Services and PGA TOUR to develop a prototype virtual assistant using Amazon Bedrock that could enable fans to extract information about any event, player, hole or shot level details in a seamless interactive manner.
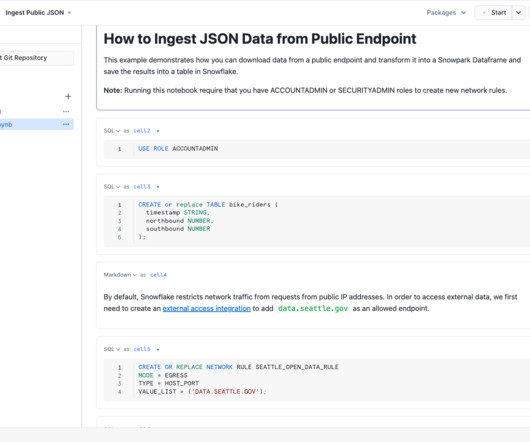
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a user name, password, and database name. For this post, we add our restaurant data. Choose Add connection.
Source: IBM Cloud Pak for Data Feature Computation Engine Users can transform batch, streaming, and real-time data into features Source: IBM Cloud Pak for Data To productionize a machine learning system, it is necessary to process new data continuously. Spark, Flink, etc.)
Fortunately, a modern data stack (MDS) using Fivetran, Snowflake, and Tableau makes it easier to pull data from new and various systems, combine it into a single source of truth, and derive fast, actionable insights. What is a modern data stack? Transparency .
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively. Dolt Dolt is an open-source relational database system built on Git. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
This unified schema streamlines downstream consumption and analytics because the data follows a standardized schema and new sources can be added with minimal datapipeline changes. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Some even provide a relational layer specifically designed for analytics, while others expose APIs.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With Apache Kafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. This section explores essential aspects of Data Engineering.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. Flink jobs, designed to process continuous data streams, are key to making this possible. They are able to adapt to changing demands quickly to seize new opportunities.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? This will also help us observe the importance of stream data. It can be used to collect, store, and process streaming data in real-time.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. Interested in attending an ODSC event?
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
In this blog, we will highlight some of the most important upcoming features and updates for those who could not attend the events, specifically around AI and developer tools. tables.create(my_table) print("Database, schema, and table created successfully.") schemas["my_schema"].tables.create(my_table) schemas["my_schema"].tables.create(my_table)
Business managers are faced with plotting the optimal course in the face of these evolving events. Pipelines must have robust data integration capabilities that integrate data from multiple data silos, including the extensive list of applications used throughout the organization, databases and even mainframes.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of datapipelines. Provenance Repository : This repository records all provenance events related to FlowFiles.
Production databases are a data-rich environment, and Fivetran would help us to migrate data by moving data from on-prem to the supported destinations; ensuring that this data remains uncorrupted throughout enhancements and transformations is crucial. We will now go over all the topics one by one.
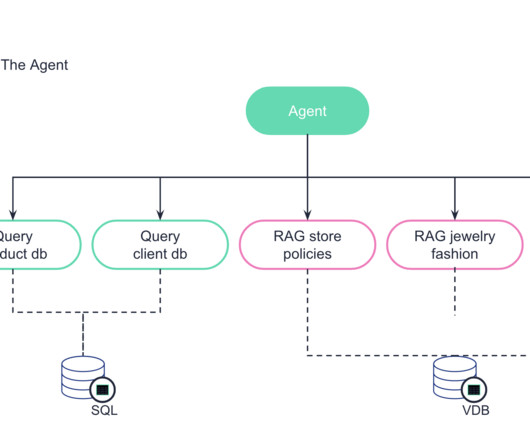
Recommend jewelry based on client's event, occasion or outfit. Capabilities include session loading, query refinement, history saving, guardrails like subject classification and a toxicity filter, connection to monitoring, the ability to iterate and retrain the model, external database connections, and more.
Fortunately, a modern data stack (MDS) using Fivetran, Snowflake, and Tableau makes it easier to pull data from new and various systems, combine it into a single source of truth, and derive fast, actionable insights. What is a modern data stack? Transparency .
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Is your data governance structure up to the task? Read What Is Data Observability?
It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime. Data observability focuses on anomaly detection before data quality rules are applied.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. In practice, tabular data is anything but clean and uncomplicated.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Interested in attending an ODSC event?
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
This tool is hosted on Hugging Face, leverages AI to continuously update its database, providing the most current and relevant information across a multitude of topics. Whether you’re managing datapipelines or deploying machine learning models, Thunder makes the process smooth and efficient.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. mp4,webm, etc.), and audio files (.wav,mp3,acc,
What is Apache Kafka, and How is it Used in Building Real-time DataPipelines? Apache Kafka is an open-source event distribution platform. It is capable of handling high-volume and high-velocity data. It is highly scalable, has high availability, and has low latency. Example: openssl rsa -in C:tmpnew_rsa_key_v1.p8
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
These systems represent data as knowledge graphs and implement graph traversal algorithms to help find content in massive datasets. These systems are not only useful for a wide range of industries, they are fun for data engineers to work on. Interested in attending an ODSC event? Learn more about our upcoming events here.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The data lake can then refine, enrich, index, and analyze that data. It truly is an all-in-one data lake solution.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content