This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL. The post Interacting with Remote Databases – PostgreSQL and DBAPIs appeared first on Analytics Vidhya.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Handling and processing the streaming data is the hardest work for Data Analysis. We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined DataPipeline appeared first on Analytics Vidhya.
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating datapipelines, and efficiently managing data warehouses.
This article was published as a part of the Data Science Blogathon. Our previous articles discussed Spark databases, installation, and working of Spark in Python. The post Machine learning Pipeline in Pyspark appeared first on Analytics Vidhya. If you haven’t read it yet, here is the link.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Code Interpreter ChatGPT Code Interpreter is a part of ChatGPT that allows you to run Python code in a live working environment. With Code Interpreter, you can perform tasks such as data analysis, visualization, coding, math, and more. You can also upload and download files to and from ChatGPT with this feature.
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
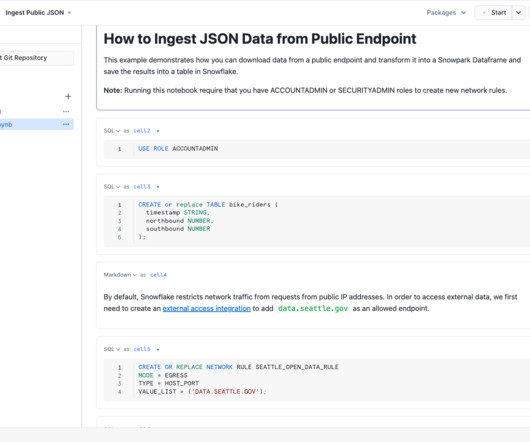
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
This orchestration process encompasses interactions with external APIs, retrieval of contextual data from vector databases, and maintaining memory across multiple LLM calls. This makes it easy to connect your datapipeline to the data sources that you need. It is known for its ease of use and flexibility.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
The visualization of the data is important as it gives us hidden insights and potential details about the dataset and its pattern, which we may miss out on without data visualization. PowerBI, Tableau) and programming languages like R and Python in the form of bar graphs, scatter line plots, histograms, and much more.
Translation memory A translation memory is a database that stores previously translated text segments (typically sentences or phrases) along with their corresponding translations. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. These tools will help make your initial data exploration process easy. You can watch it on demand here.
This better reflects the common Python practice of having your top level module be the project name. The goal is to have more comprehensive documentation: A new more modern theme + look An example of how to use the template Links and documentation for the tools you can choose from that solve particular tasks in the data science stack.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. In this blog, we’ll cover the steps to get started, including: How to set up an existing Snowpark project on your local system using a Python IDE.
Python is the top programming language used by data engineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Automation Automating datapipelines and models ➡️ 6. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. The Data Engineer Not everyone working on a data science project is a data scientist.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Snowflake announced many new features that will enhance development and collaboration: Snowflake Notebooks: Currently available in public preview, Snowflake notebooks provide a notebook interface that enables data teams to collaborate with Python and SQL in one place. Furthermore, Snowflake Notebooks can also be run on a schedule.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Amazon DynamoDB is a fast and flexible nonrelational database service for any scale. The ML model is trained from pet profiles pulled from Purina’s database, assuming the primary breed label is the true label. AWS CodeBuild is a fully managed continuous integration service in the cloud. DynamoDB is used to store the pet attributes.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select.
This article was published as a part of the Data Science Blogathon. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. This section explores essential aspects of Data Engineering.
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
A feature store is a data platform that supports the creation and use of feature data throughout the lifecycle of an ML model, from creating features that can be reused across many models to model training to model inference (making predictions). It can also transform incoming data on the fly. All of them are written in Python.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Python code that calls an LLM), or should it be driven by an AI model (e.g. Likewise, in a compound system, where should a developer invest resources—for example, in a RAG pipeline, is it better to spend more FLOPS on the retriever or the LLM, or even to call an LLM multiple times? LLM agents that call external tools)?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content