This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. This article dives into the core functionalities of dbt, exploring its unique strengths and how […] The post Transforming Your DataPipeline with dbt(data build tool) appeared first on Analytics Vidhya.
Relational Graph Transformers represent the next evolution in Relational DeepLearning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.
This article was published as a part of the Data Science Blogathon. Introduction A deeplearning task typically entails analyzing an image, text, or table of data (cross-sectional and time-series) to produce a number, label, additional text, additional images, or a mix of these.
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
Photo by AltumCode on Unsplash As a data scientist, I used to struggle with experiments involving the training and fine-tuning of large deep-learning models. Kedro, an open-source toolbox, provides an efficient template for conducting experiments in machine learning. Inputs and outputs are sourced from the data catalog.
Hammerspace, the company orchestrating the Next Data Cycle, unveiled the high-performance NAS architecture needed to address the requirements of broad-based enterprise AI, machine learning and deeplearning (AI/ML/DL) initiatives and the widespread rise of GPU computing both on-premises and in the cloud.
Neuron is the SDK used to run deeplearning workloads on Trainium and Inferentia based instances. High latency may indicate high user demand or inefficient datapipelines, which can slow down response times.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment?
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know data science and in turn, NLP.
Type of Data: structured and unstructured from different sources of data Purpose: Cost-efficient big data storage Users: Engineers and scientists Tasks: storing data as well as big data analytics, such as real-time analytics and deeplearning Sizes: Store data which might be utilized.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
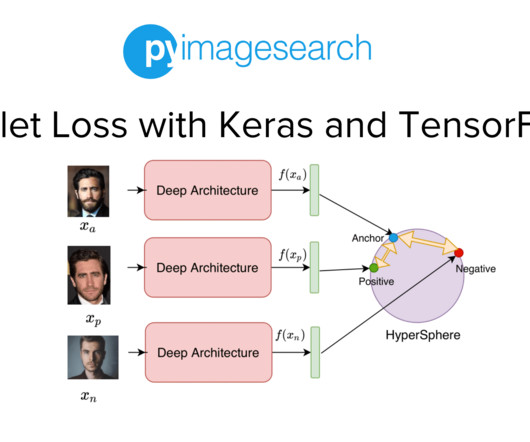
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. That’s not the case.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your DeepLearning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core?
The platform handles: Automatic model deployment Load balancing High availability Security compliance Model monitoring and updating Integration with the Broader AWS Machine Learning Ecosystem One often-overlooked advantage is the seamless integration with other AWS services. medium notebook instances for development 50 hours per month of m4.xlarge
In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a data engineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists.
Machine learning The 6 key trends you need to know in 2021 ? Automation Automating datapipelines and models ➡️ 6. First, let’s explore the key attributes of each role: The Data Scientist Data scientists have a wealth of practical expertise building AI systems for a range of applications.
Introduction Data science is a practical subject that the experts can best explain in the field. These sessions will enhance your domain knowledge and help you learn new […].
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. He works to enable the development, training, and production inference of deeplearning.
Monte Carlo Monte Carlo is a popular data observability platform that provides real-time monitoring and alerting for data quality issues. It could help you detect and prevent datapipeline failures, data drift, and anomalies. Metaplane supports collaboration, anomaly detection, and data quality rule management.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible.
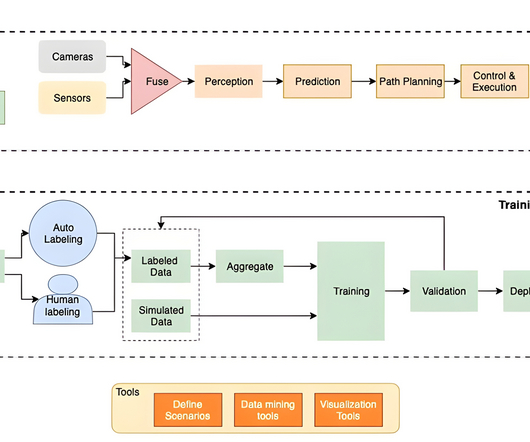
Solution overview In brief, the solution involved building three pipelines: Datapipeline – Extracts the metadata of the images Machine learningpipeline – Classifies and labels images Human-in-the-loop review pipeline – Uses a human team to review results The following diagram illustrates the solution architecture.
Meme shared by bin4ry_d3struct0r TAI Curated section Article of the week Graph Neural Networks (GNN) — Concepts and Applications by Tan Pengshi Alvin Graph Neural Networks (GNN) are a very interesting application in deeplearning and have strong potential for important use cases, albeit a less well-known and more niche domain.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
To solve this problem, we had to design a strong datapipeline to create the ML features from the raw data and MLOps. Multiple data sources ODIN is an MMORPG where the game players interact with each other, and there are various events such as level-up, item purchase, and gold (game money) hunting.
. “Keras (3) Is All You Need” — A Presentation by Aritra and Aakash At its core , deeplearning involves manipulating multi-dimensional arrays known as tensors. These tensors represent various forms of data (e.g., which are essential for building deeplearning models. images, sound, and text).
SageMaker has developed the distributed data parallel library , which splits data per node and optimizes the communication between the nodes. You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. Therefore, BMW established a centralized ML/deeplearning infrastructure on premises several years ago and continuously upgraded it.
AI Engineering TrackBuild Scalable AISystems Learn how to bridge the gap between AI development and software engineering. This track will focus on AI workflow orchestration, efficient datapipelines, and deploying robust AI solutions. This track provides practical guidance on building and optimizing deep learningsystems.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
As you’ll see in the next section, data scientists will be expected to know at least one programming language, with Python, R, and SQL being the leaders. This will lead to algorithm development for any machine or deeplearning processes.
He focuses on Deeplearning including NLP and Computer Vision domains. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He helps customers achieve high performance model inference on SageMaker.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
TL;DR GPUs can greatly accelerate deeplearning model training, as they are specialized for performing the tensor operations at the heart of neural networks. We’ll explore how factors like batch size, framework selection, and the design of your datapipeline can profoundly impact the efficient utilization of GPUs.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Project Structure Creating Adversarial Examples Robustness Toward Adversarial Examples Summary Citation Information Adversarial Learning with Keras and TensorFlow (Part 1): Overview of Adversarial Learning In this tutorial, you will learn about adversarial examples and how they affect the reliability of neural network-based computer vision systems.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.”
Furthermore, we also import the keras library ( Line 6 ), tensorflow library ( Line 7 ), numpy ( Line 8 ), and os module ( Line 9 ) for various deeplearning or matrix or manipulation functionalities, as always. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated?
Keeping track of changes in data, model parameters, and infrastructure configurations is essential for reliable AI development, ensuring models can be rebuilt and improved efficiently. Building Scalable DataPipelines The foundation of any AI pipeline is the data it consumes.
Thirdly, the presence of GPUs enabled the labeled data to be processed. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed.
Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines. It also simplifies managing configuration dependencies in DeepLearning projects and large-scale datapipelines.
I led several projects that dramatically advanced the company’s technological capabilities: Real-time Video Analytics for Security: We developed an advanced system integrating deeplearning algorithms with existing CCTV infrastructure.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content