This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
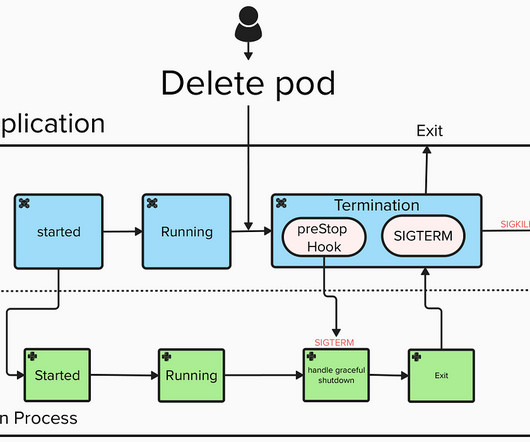
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
In essence, DataOps is a practice that helps organizations manage and govern data more effectively. However, there is a lot more to know about DataOps, as it has its own definition, principles, benefits, and applications in real-life companies today – which we will cover in this article! Automated testing to ensure data quality.
Definition and functionality of LLM app platforms These platforms encompass various capabilities specifically tailored for LLM development. Data annotation: Adding relevant metadata to enhance the model’s learning capabilities. KLU.ai: Offers no-code solutions for smooth data source integration.
Definition These failures often stem from biased training data, flawed feature selection, or insufficient representation of minority groups in datasets. Model failures Model failures often stem from issues within the datapipeline, which is vital for sustaining model performance.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Machine Learning Operations (MLOps): Overview, Definition, and Architecture (by Kreuzberger, et al., AIIA MLOps blueprints.
Source: IBM Cloud Pak for Data Feature Catalog Users can manage feature definitions and enrich them with metadata, such as tags, transformation logic, or value descriptions. Source: IBM Cloud Pak for Data MLOps teams often struggle when it comes to integrating into CI/CD pipelines. Spark, Flink, etc.)
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
The agent can generate SQL queries using natural language questions using a database schema DDL (datadefinition language for SQL) and execute them against a database instance for the database tier. We use Amazon Bedrock Agents with two knowledge bases for this assistant.
This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline. To create a UDN, we’ll need a node definition that defines how the node should function and templates for how the object will be created and run.
Data science is an interdisciplinary field that utilizes advanced analytics techniques to extract meaningful insights from vast amounts of data. This helps facilitate data-driven decision-making for businesses, enabling them to operate more efficiently and identify new opportunities.
With their technical expertise and proficiency in programming and engineering, they bridge the gap between data science and software engineering. By recognizing these key differences, organizations can effectively allocate resources, form collaborative teams, and create synergies between machine learning engineers and data scientists.
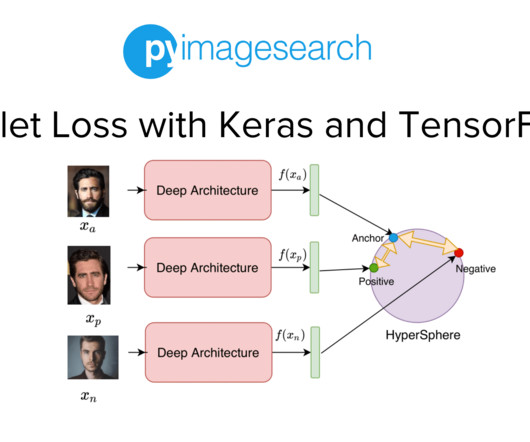
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. The following figure shows schema definition and model which reference it.
It may conflict with your data governance policy (more on that below), but it may be valuable in establishing a broader view of the data and directing you toward better data sets for your main models. Datapipeline maintenance. It adds a layer of bureaucracy to data engineering that you may like to avoid.
With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable data models to build a trusted foundation for analytics. Connecting directly to this semantic layer will help give customers access to critical business data in a safe, governed manner. Direct connection to Google BigQuery.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. With this Spark connector, you can easily ingest data to the feature group’s online and offline store from a Spark DataFrame.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss.
Designing the prompt Before starting any scaled use of generative AI, you should have the following in place: A clear definition of the problem you are trying to solve along with the end goal. When you evaluate a case, evaluate the definitions in order and label the case with the first definition that fits.
Alation’s deep integration with tools like MicroStrategy and Tableau provides visibility into the complete datapipeline: from storage through visualization. Many of our customers have been telling us that these two tools in particular form the core of their visual analytics environments.
To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. Much of what we found was to be expected, though there were definitely a few surprises. You’ll see specific tools in the next section.
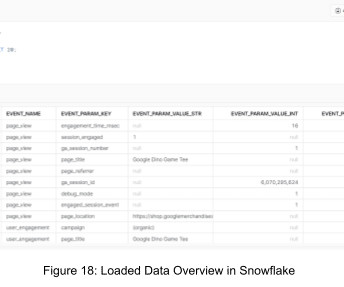
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. This allows you to control which IAM principals are allowed to decrypt the data and view it. For testing, choose yes.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deep learning models that are pre-trained with attention mechanisms on massive datasets. This helps cleanse the data.
Data governance Apply fine-grained access control to data managed by the system, including training data, vector stores, evaluation data, prompt templates, workflow, and agent definitions.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
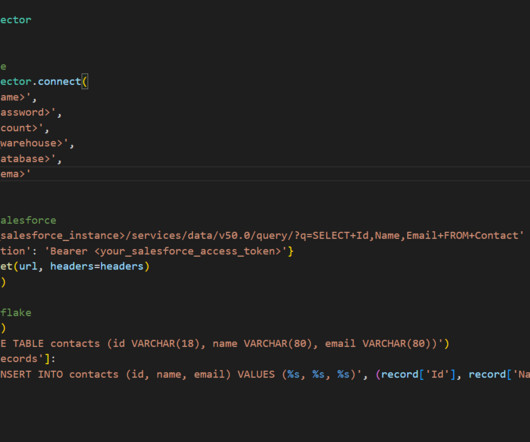
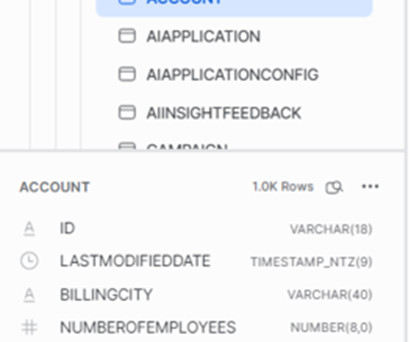
Third-Party Tools Third-party tools like Matillion or Fivetran can help streamline the process of ingesting Salesforce data into Snowflake. With these tools, businesses can quickly set up datapipelines that automatically extract data from Salesforce and load it into Snowflake.
Matillion’s Data Productivity Cloud is a versatile platform designed to increase the productivity of data teams. It provides a unified platform for creating and managing datapipelines that are effective for both coders and non-coders.
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side. This is a very good thing.
With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable data models to build a trusted foundation for analytics. Connecting directly to this semantic layer will help give customers access to critical business data in a safe, governed manner. Direct connection to Google BigQuery.
Hello from our new, friendly, welcoming, definitely not an AI overlord cookie logo! The second is to provide a directed acyclic graph (DAG) for datapipelining and model building. The vision for V2 is to give CCDS users more flexibility while still making a great template if you just put your hand over your eyes and hit enter.
For any data user in an enterprise today, data profiling is a key tool for resolving data quality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
It integrates smoothly with other data processing libraries like Spark, Pandas, NumPy, and more, as well as ML frameworks like TensorFlow and PyTorch. This allows building end-to-end datapipelines and ML workflows on top of Ray. The goal is to make distributed data processing and ML easier for practitioners and researchers.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
Transition to the Data Cloud With multiple ways to interact with your company’s data, Snowflake has built a common access point that handles data lake access, data warehouse access, and data sharing access into one protocol. What kinds of Workloads Does Snowflake Handle?
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of datapipelines.
Conclusion Integrating Salesforce data with Snowflake’s Data Cloud using Tableau CRM Sync Out can benefit organizations by consolidating internal and third-party data on a single platform, making it easier to find valuable insights while removing the challenges of data silos and movement.
It is a process for moving and managing data from various sources to a central data warehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
A typical Airflow DAG includes multiple tasks, such as extracting data from APIs, transforming it, and loading it into a data warehouse. Below is a simple Airflow DAG definition: Airflow revolutionized ETL pipeline orchestration, but Generative AI is now adding a new layer of intelligence.
The data source tool can also directly generate the DataDefinition Language (DDL) for these tables as well if you decide not to use dbt! This allows you to better understand the existing structures that are in place and more accurately perform your migration (or generate documentation, everybody’s favorite!).
lossTracker=keras.metrics.Mean(name="loss"), ) Loading the Trained Siamese Model for Evaluation Now that we have completed the definition of our metrics function, let us load our trained Siamese model and evaluate its performance. On Line 29 , we get our modelPath , where we save our trained Siamese model after training.
Let’s briefly look at the key components and their roles in this process: Azure Data Factory (ADF) : ADF will serve as our data orchestration and integration platform. It enables us to create, schedule, and monitor the datapipeline, ensuring seamless movement of data between the various sources and destinations.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content