This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
Data scientists are also some of the highest-paid job roles, so data scientists need to quickly show their value by getting to real results as quickly, safely, and accurately as possible. Set up a datapipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
But again, stick around for a surprise demo at the end. ? This format made for a fast-paced and diverse showcase of ideas and applications in AI and ML. In just 3 minutes, each participant managed to highlight the core of their work, offering insights into the innovative ways in which AI and ML are being applied across various fields.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. Enter a stack name, such as Demo-Redshift. yaml locally.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. These models are then pushed to an Amazon Simple Storage Service (Amazon S3) bucket using DVC, a version control tool for ML models. Thirdly, there are improvements to demos and the extension for Spark.
For data science practitioners, productization is key, just like any other AI or ML technology. Successful demos alone just won’t cut it, and they will need to take implementation efforts into consideration from the get-go, and not just as an afterthought. AI/ML Predictions for the New Year appeared first on Iguazio.
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications. Atlas Vector Search lets you search unstructured data.
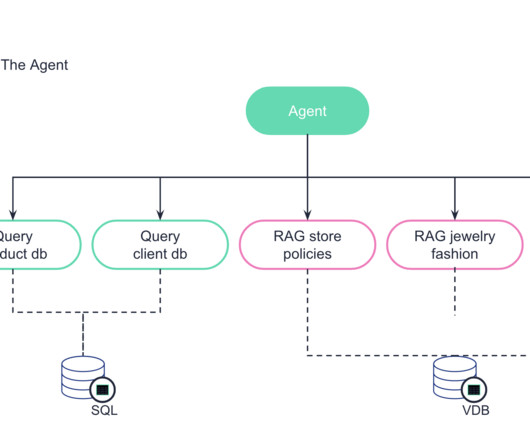
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. On the Import data page, for Data Source , choose DocumentDB and Add Connection.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
For data science practitioners, productization is key, just like any other AI or ML technology. Successful demos alone just won’t cut it, and they will need to take implementation efforts into consideration from the get-go, and not just as an afterthought. AI/ML Predictions for the New Year appeared first on Iguazio.
Boost productivity – Empowers knowledge workers with the ability to automatically and reliably summarize reports and articles, quickly find answers, and extract valuable insights from unstructured data. The following demo shows Agent Creator in action. He currently is working on Generative AI for data integration.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. Optimization Often in ML, maximizing the quality of a compound system requires co-optimizing the components to work well together.
With Composable ML , expert data scientists can extend DataRobot’s AutoML blueprints with their domain knowledge and custom code. Composable ML turns DataRobot blueprints into reusable building blocks. Request a Demo. Jump-Start Your AI Journey Today. The post Advancing AI Cloud with Release 7.2
This situation is not different in the ML world. Data Scientists and ML Engineers typically write lots and lots of code. Directives and architectural tricks for robust datapipelines Gain insights into an extensive array of directives and architectural strategies tailored for the development of highly dependable datapipelines.
Demo: How to Build a Smart GenAI Call Center App How we used LLMs to turn call center conversation audio files of customers and agents into valuable data in a single workflow orchestrated by MLRun. For example, when indexing a new version of a document, it’s important to take care of versioning in the MLpipeline.
In this blog post, we provide a staged approach for rolling out gen AI, together with use cases, a demo and examples that you can implement and follow. The webinar hosts Eli Stein, Partner and Modern Marketing Capabilities Leader from McKinsey, Ze’ev Rispler, ML Engineer, from Iguazio (acquired by McKinsey), and myself.
Data scientists drive business outcomes. Many implement machine learning and artificial intelligence to tackle challenges in the age of Big Data. They develop and continuously optimize AI/ML models , collaborating with stakeholders across the enterprise to inform decisions that drive strategic business value. Download Now.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Tuesday is the first day of the AI Expo and Demo Hall , where you can connect with our conference partners and check out the latest developments and research from leading tech companies. Finally, get ready for some All Hallows Eve fun with Halloween Data After Dark , featuring a costume contest, candy, and more. What’s next?
For this architecture, we propose an implementation on GitHub , with loosely coupled components where the backend (5), datapipelines (1, 2, 3) and front end (4) can evolve separately. Choose the link with the following format to open the demo: [link]. Inside the frontend/streamlit-ui folder, run bash run-streamlit-ui.sh.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a datapipeline. Conclusion To get started today with SnapGPT, request a free trial of SnapLogic or request a demo of the product. He currently is working on Generative AI for data integration.
In this blog, we’ll show you how to build a robust energy price forecasting solution within the Snowflake Data Cloud ecosystem. We’ll cover how to get the data via the Snowflake Marketplace, how to apply machine learning with Snowpark , and then bring it all together to create an automated ML model to forecast energy prices.
Familiar Client Side Libraries – Snowpark brings in-house and deeply integrated, DataFrame-style programming abstract and OSS-compatible APIs to the languages data practitioners like to use (Python, Scala, etc). It also includes the Snowpark ML API for more efficient machine language (ML) modeling and ML operations.
While this year the BI Bake Off is designed for BI vendors, we wanted to show how the Alation Data Catalog can help make the analysis of this important dataset more effective and efficient. . Alation BI Bake Off Demo. With Alation, you can search for assets across the entire datapipeline.
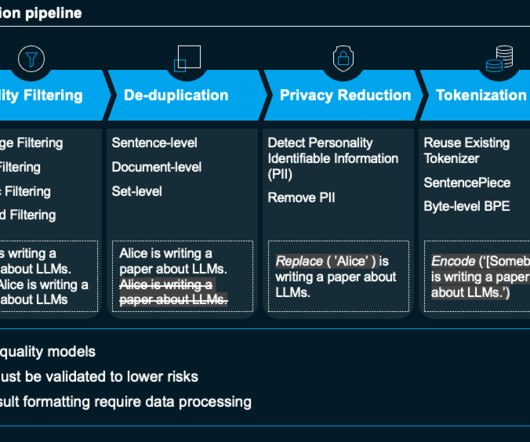
They are characterized by their enormous size, complexity, and the vast amount of data they process. These elements need to be taken into consideration when managing, streamlining and deploying LLMs in MLpipelines, hence the specialized discipline of LLMOps. Continuous monitoring of resources, data, and metrics.
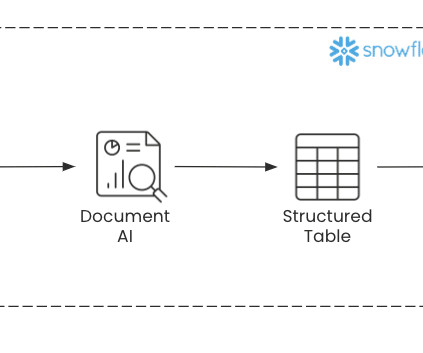
By harnessing the advancements of LLMs, users can now extract key information buried within large documents without any code or ML knowledge required. Before we dive into the demo, the next section covers a couple of the key technologies that enable Document AI. Document AI is a new Snowflake tool that ingests documents (e.g.,
Building MLOpsPedia This demo on Github shows how to fine tune an LLM domain expert and build an ML application Read More Building Gen AI for Production The ability to successfully scale and drive adoption of a generative AI application requires a comprehensive enterprise approach. Let’s dive into the data management pipeline.
And there’s a growing consensus that dumping all data into the cloud data warehouse is too expensive to be sustainable – though presenters expressed doubt that this may be the case for just small use cases. So, how can a data catalog support the critical project of building datapipelines?
Machine learning, particularly its subsets, deep learning, and generative ML, is currently in the spotlight. While many businesses believe that ML-driven automation is key to their success, a survey by McKinsey shows that only 15% of businesses’ ML projects ever succeed. What is Machine Learning Model Testing?
Machine learning, particularly its subsets, deep learning, and generative ML, is currently in the spotlight. While many businesses believe that ML-driven automation is key to their success, a survey by McKinsey shows that only 15% of businesses’ ML projects ever succeed. What is Machine Learning Model Testing?
Request a demo to see how watsonx can put AI to work There’s no AI, without IA AI is only as good as the data that informs it, and the need for the right data foundation has never been greater. A data lakehouse with multiple query engines and storage can allow engineers to share data in open formats.
Access the resources your data applications need — no more, no less. DataPipeline Automation. Consolidate all data sources to automate pipelines for processing in a single repository. For example, as you build out your data modernization initiative you need to consider: Before Migration: What data is popular?
Strategies for improving GPU usage include mixed-precision training, optimizing data transfer and processing, and appropriately dividing workloads between CPU and GPU. GPU and CPU metrics can be monitored using an ML experiment tracker like Neptune, enabling teams to identify bottlenecks and systematically improve training performance.
Finally, Week 4 ties it all together, guiding participants through the practical builder demos from cloning compound AI architectures to building production-ready applications. Cloning NotebookLM with Open Weights Models Niels Bantilan, Chief ML Engineer atUnion.AI
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do data analysis BI report generation/data analysis In BI/data analysis world, people usually need to query data (small/large).
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. Optimization Often in ML, maximizing the quality of a compound system requires co-optimizing the components to work well together.
This approach incorporates relevant data from a data store into prompts, providing large language models with additional context to help answer queries. Conclusion This blog has only covered the minimum technologies required to build the bare bones of a generative AI application.
Data scientists use data-driven approaches to enable AI systems to make better predictions, optimize decision-making, and uncover hidden patterns that ultimately drive innovation and improve performance across various domains. It includes techniques like supervised, unsupervised, and reinforcement learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content