This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Josep Ferrer , KDnuggets AI Content Specialist on July 15, 2025 in Data Science Image by Author Delivering the right data at the right time is a primary need for any organization in the data-driven society. But lets be honest: creating a reliable, scalable, and maintainable datapipeline is not an easy task.
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 19, 2025 in Programming Image by Author | Ideogram Youre architecting a new datapipeline or starting an analytics project, and you’re probably considering whether to use Python or Go. We compare Go and Python to help you make an informed decision.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
Document Everything : Keep clear and versioned documentation of how each feature is created, transformed, and validated. Use Automation : Use tools like feature stores, pipelines, and automated feature selection to maintain consistency and reduce manual errors.
Feeding data for analytics Integrated data is essential for populating data warehouses, data lakes, and lakehouses, ensuring that analysts have access to complete datasets for their work. Best practices for data integration Implementing best practices ensures successful data integration outcomes.
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. For this post, we use a document store. Choose With Document Store.
Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning datapipelines.
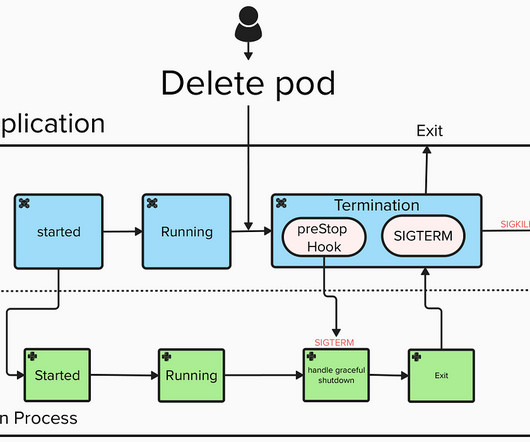
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. Without the capabilities of Tecton , the architecture might look like the following diagram.
Use case In this example of an insurance assistance chatbot, the customers generative AI application is designed with Amazon Bedrock Agents to automate tasks related to the processing of insurance claims and Amazon Bedrock Knowledge Bases to provide relevant documents. getOutstandingPaperwork What are the missing documents from {{claim}}?
The metadata for each Q topic—including name, description, available metrics, dimensions, and sample questions—is converted into a searchable document and embedded using the Amazon Titan Text Embeddings V2 model. Lakshdeep Vatsa is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
This fragmented approach consumed valuable time and introduced the risk of human error in data interpretation and analysis. The initial implementation established basic RAG functionality by feeding the Amazon Bedrock knowledge base with tabular data and documentation. The solution architecture evolved through several iterations.
Clean, interoperable datapipelines : Having region-specific analytics, differentiated content such as marketing materials translated into various languages, and numerous CRM instances all add up to global operations. Consistent execution requires defined change management workflows and clearly delineated onboarding documentation.
This personalized document helps the customer gain a deeper understanding of the vehicle and supports their decision-making process. The Amazon Titan Embeddings G1 Text LLM is used to convert the knowledge documents and user queries into vector embeddings.
When needed, the system can access an ODAP data warehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks. Emel Mendoza is a Senior Solutions Architect at AWS based in the Netherlands.
Comments and Notes: Documenting for Future You (or Someone Else) Good documentation makes life easiernot just for you but for anyone who might need to pick up your work later. Document business rules and assumptions directly within the workflow. Data tables used and their role in the workflow. success, failure, review).
Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale datapipelines.
Sources of Data in the Pile The Pile draws from a variety of sources to ensure richness and reliability. Open-access books, encyclopedias, and government documents offer well-structured, factual content. It also features data from novels, legal documents, and medical texts.
For building and designing software applications, you will use the existing Knowledge Base on AWS well-architected framework to generate a response of the most relevant design principles and links to any documents. Amazon Bedrock Knowledge Bases inherently uses the Retrieval Augmented Generation (RAG) technique.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
Musani emphasized the massive scale: “More than a million users doing 30,000 queries a day…that’s massive things happening on such rich data.” Unified datapipelines connect the supply chain to the store floor. As Musani explains: “We have built element in a way where it makes it agnostic to different llms as well, right? “We
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Assess your current data landscape and identify data sources Once you know the goals and scope of your project, map your current IT landscape to your project requirements. This is how youll identify key data stores and repositories where your most critical and relevant data lives.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Data collection and preparation Quality data is paramount in training an effective LLM. Developers collect data from various sources such as APIs, web scrapes, and documents to create comprehensive datasets. Subpar data can lead to inaccurate outputs and diminished application effectiveness.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. Oh, also, I'm great at writing documentation.
As AI and data engineering continue to evolve at an unprecedented pace, the challenge isnt just building advanced modelsits integrating them efficiently, securely, and at scale. This session explores open-source tools and techniques for transforming unstructured documents into structured formats like JSON and Markdown.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
For real estate queries, you need the property details and source documents right there. They treat evaluation criteria as living documents that evolve alongside their understanding of the problem space. When reviewing apartment leasing conversations, you need to see the full chat history and scheduling context.
From summarizing complex legal documents to powering advanced chat-based assistants, AI capabilities are expanding at an increasing pace. While large language models (LLMs) continue to push new boundaries, quality data remains the deciding factor in achieving real-world impact.
Amazon Elastic Kubernetes Service (Amazon EKS) retrieves data from Amazon DocumentDB , processes it, and invokes Amazon Bedrock Agents for reasoning and analysis. This structured datapipeline enables optimized pricing strategies and multilingual customer interactions.
Give us feedback → Edit this page Scroll to top Blog Why Go is a good fit for agents Why Go is a good fit for agents Since you’re here, you might be interested in checking out Hatchet — the platform for running background tasks, datapipelines and AI agents at scale. They often involve input from a user (or another agent!)
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
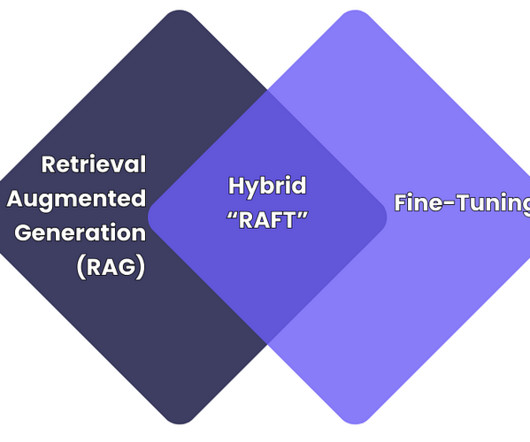
RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., Chunking Issues Problem: The poor chunk size leads to incomplete context or irrelevant document retrieval.
Designing AI datapipelines to process billions of data points. Open roles include: • Senior ML/Data Engineers • Senior AI Consultants • Senior AI Project Managers • Industry Directors • Junior ML/Data Engineers and many more!
Do you know if the FPGA and/or hardware communities use any type of formalism for design or documentation of state machines? Subscribers, ahem secret agents, receive packages every few weeks containing reproductions of famous documents, stanps from the USSR, Cuba, Czechoslovakia, coins, and other fun stuff.
They then proceeded to spend about six months in a windowless office far less plush than that of John Smedley, creating a design document for the game that they were already calling EverQuest ; the name had felt so right as soon as it was proposed by Clover that another one was never seriously discussed.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content