This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning datapipelines.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
However, they can’t generalize well to enterprise-specific questions because, to generate an answer, they rely on the public data they were exposed to during pre-training. However, the popular RAG design pattern with semantic search can’t answer all types of questions that are possible on documents.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
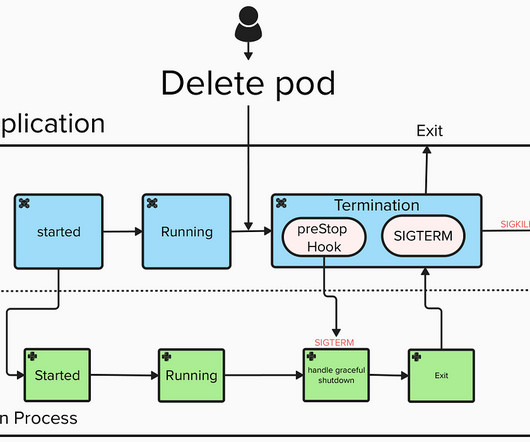
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
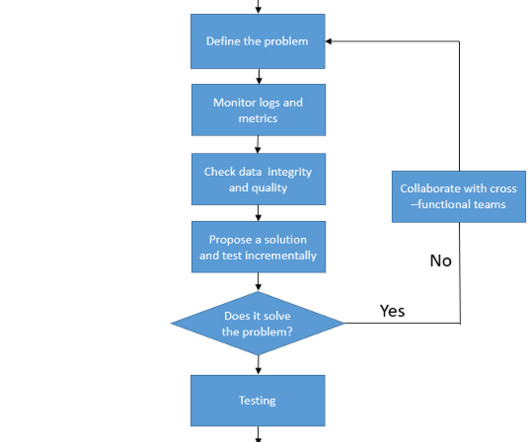
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. For this post, we use a document store. Choose With Document Store.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
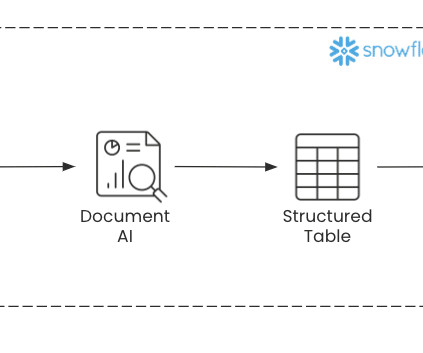
With an endless stream of documents that live on the internet and internally within organizations, the hardest challenge hasn’t been finding the information, it is taking the time to read, analyze, and extract it. What is Document AI from Snowflake? Document AI is a new Snowflake tool that ingests documents (e.g.,
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). Project documentation ¶ As data science codebases live longer, code is often refactored into a package.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc.
The raw data can be fed into a database or data warehouse. An analyst can examine the data using business intelligence tools to derive useful information. . To arrange your data and keep it raw, you need to: Make sure the datapipeline is simple so you can easily move data from point A to point B.
Provide connectors for data sources: Orchestration frameworks typically provide connectors for a variety of data sources, such as databases, cloud storage, and APIs. This makes it easy to connect your datapipeline to the data sources that you need.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
When needed, the system can access an ODAP data warehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks. Emel Mendoza is a Senior Solutions Architect at AWS based in the Netherlands.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. Without the capabilities of Tecton , the architecture might look like the following diagram.
Photo by AltumCode on Unsplash As a data scientist, I used to struggle with experiments involving the training and fine-tuning of large deep-learning models. It facilitates the creation of various datapipelines, including tasks such as data transformation, model training, and the storage of all pipeline outputs.
Assess your current data landscape and identify data sources Once you know the goals and scope of your project, map your current IT landscape to your project requirements. This is how youll identify key data stores and repositories where your most critical and relevant data lives.
Watto securely uses this contextual data to build high quality documents/reports that employees spend quarters in writing and getting reviewed. Watto uses AI to automatically generate high quality documents and reports. Over time, our proprietary LLMs fine-tune and learn to become your team’s star performer.
This code is often the true source of record for how data has been transformed as it weaves its way into ML training data sets. Make it a required practice to document all data sources : Documentingdata sources and providing clear descriptions of how data has been transformed can help establish trust in ML conclusions.
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
With the help of the insights, we make further decisions on how to experiment and optimize the data for further application of algorithms for developing prediction or forecast models. What are ETL and datapipelines? These datapipelines are built by data engineers.
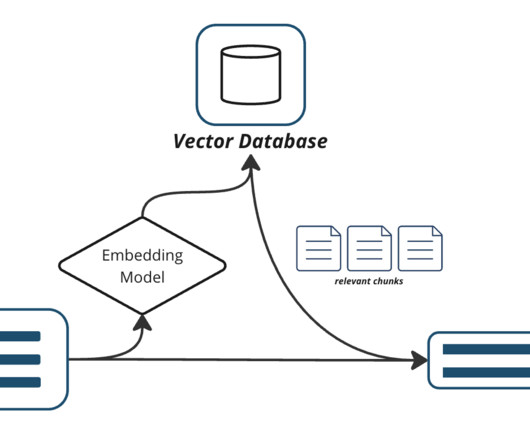
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
Amazon Kendra is a fully managed service that provides out-of-the-box semantic search capabilities for state-of-the-art ranking of documents and passages. I can help you with queries based on the documents provided. The welcome intent is configured to respond with a greeting when a user enters a greeting such as “hi” or “hello.”
Key Metrics Annotation Time Reduction : Reduced document annotation time by 75%. Operational Speed : Accelerated data processing pipeline, achieving a 50% increase in data processing speed. Their primary challenges included: Data inconsistencies from non-standardized documentation.
To enable quick information retrieval, we use Amazon Kendra as the index for these documents. Amazon Kendra uses natural language processing (NLP) to understand user queries and find the most relevant documents. Mike Amjadi is a Data & ML Engineer with AWS ProServe focused on enabling customers to maximize value from data.
Increased datapipeline observability As discussed above, there are countless threats to your organization’s bottom line. That’s why datapipeline observability is so important. With data lineage, every object in the migrated system is mapped and dependencies are documented.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Multi-Modal : Alongside structured data, there's a growing need for semi-structured and unstructured data in gen AI applications. MongoDB's multi-modal document model allows you to handle diverse data types, including documents, network/knowledge graph, geospatial data, and time series data, and to process them.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. 5 Key Comparisons in Different Apache Kafka Architectures.
Aleks ensured the model could be implemented without complications by delivering structured outputs and comprehensive documentation. Yunus focused on building a robust datapipeline, merging historical and current-season data to create a comprehensive dataset.
It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
By using Fivetran, businesses can reduce the time and resources required for data integration, enabling them to focus on extracting insights from the data rather than managing the ELT process. Building datapipelines manually is an expensive and time-consuming process. Why Use Fivetran?
Refer to the Kafka documentation and relevant monitoring tools to understand the specific metrics available for your version of Kafka and how to interpret them effectively. Monitoring your IBM® Event Streams for IBM Cloud® instance is crucial to ensure optimal functionality and overall health of your datapipeline.
Once your information is organized, a data observability tool can take your data quality efforts to the next level by managing data drift or schema drift before they break your datapipelines or affect any downstream analytics applications. What Does a Data Catalog Do?
Great Expectations GitHub | Website Great Expectations (GX) helps data teams build a shared understanding of their data through quality testing, documentation, and profiling. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
David: My technical background is in ETL, data extraction, data engineering and data analytics. I spent over a decade of my career developing large-scale datapipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems.
Failing to make production data accessible in the cloud. Data professionals often enable many different cloud-native services to help users perform distributed computations, build and store container images, create datapipelines, and more. Centralise new data and computational resources.
Using this realistic synthetic data, users can: Enable development or create a POC before the real data is available. Test datapipelines without needing access to sensitive data. Test specific scenarios in datapipelines (like error handling or outlier detection).
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘Data Engineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content