This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
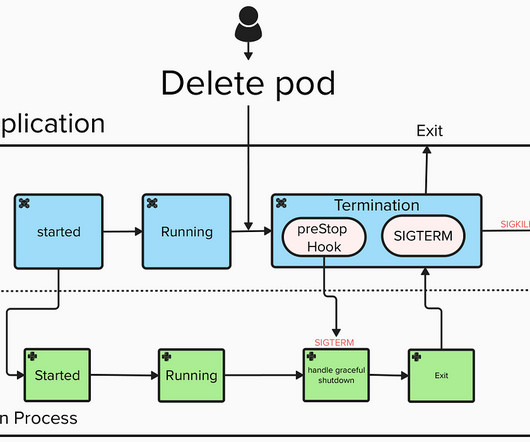
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. For this post, we use a document store. Choose With Document Store.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick.
With the help of the insights, we make further decisions on how to experiment and optimize the data for further application of algorithms for developing prediction or forecast models. What are ETL and datapipelines? These datapipelines are built by data engineers.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This code is often the true source of record for how data has been transformed as it weaves its way into ML training data sets. Make it a required practice to document all data sources : Documentingdata sources and providing clear descriptions of how data has been transformed can help establish trust in ML conclusions.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Assess your current data landscape and identify data sources Once you know the goals and scope of your project, map your current IT landscape to your project requirements. This is how youll identify key data stores and repositories where your most critical and relevant data lives.
It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Fivetran’s automated data movement platform simplifies the ETL (extract, transform, load) process by automating most of the time-consuming tasks of ETL that data engineers would typically do.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, data engineering and data analytics. For each query, an embeddings query identifies the list of best matching documents.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Complexity limits accessibility and value creation.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Why Does it Matter?
How can an organization enable flexible digital modernization that brings together information from multiple data sources, while still maintaining trust in the integrity of that data? To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
Putting the T for Transformation in ELT (ETL) is essential to any datapipeline. After extracting and loading your data into the Snowflake AI Data Cloud , you may wonder how best to transform it. Coalesce’s top features include column-level lineage and auto-generated documentation.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
Matillion’s Data Productivity Cloud is a versatile platform designed to increase the productivity of data teams. It provides a unified platform for creating and managing datapipelines that are effective for both coders and non-coders. Check out the API documentation for our sample.
Documentation: Keep detailed documentation of the deployed model, including its architecture, training data, and performance metrics, so that it can be understood and managed effectively. If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Gain hands-on experience with data integration: Learn about data integration techniques to combine data from various sources, such as databases, spreadsheets, and APIs. BI Developer Skills Required To excel in this role, BI Developers need to possess a range of technical and soft skills.
May be useful Best Workflow and Pipeline Orchestration Tools: Machine Learning Guide Phase 1—Datapipeline: getting the house in order Once the dust was settled, we got the Architecture Canvas completed, and the plan was clear to everyone involved, the next step was to take a closer look at the architecture. What’s in the box?
Coalesce is quickly becoming the go-to ETL tool due to its unique code-first approach and low-code/no-code interface blend. Its easy handling of complex data environments makes it an ideal choice for modern enterprises. Utilize branches to develop your datapipelines effectively.
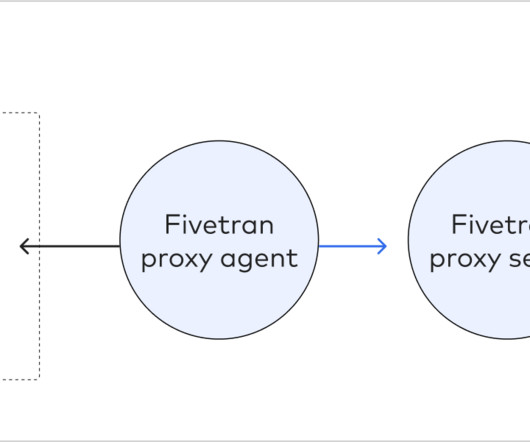
The on-premise agent is responsible for sending data to Fivetran, which is then processed and loaded into the destination. You can find more information about them in their official documentation. Speed: The agent on the source database will filter the data before sending it through the datapipeline.
It truly is an all-in-one data lake solution. HPCC Systems and Spark also differ in that they work with distinct parts of the big datapipeline. Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination.
Natural Language Understanding (NLU) : NLU is a subset of NLP focused on algorithms that can interpret the meaning of a sentence or document in terms of syntax, grammar, or ontology. That act of data collection and enrichment is enabled and accelerated by a modern data stack.
Datapipeline orchestration tools are designed to automate and manage the execution of datapipelines. These tools help streamline and schedule data movement and processing tasks, ensuring efficient and reliable data flow. What are Orchestration Tools?
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a datapipeline. So this will return all customer documents from the ExampleCompany database where the status field is set to “active”. We use the following prompt: Human: Your job is to act as an expert on ETLpipelines.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETLpipelines that cause decisions to be made on stale or old data.
Notebooks like Jupyter have also emerged as essential tools by combining documentation, code execution, and visualization in a single interactive interface. This allows iterative data analysis workflows rather than rigid scripts. The most skilled data scientists may leverage these starting-point recommendations to boost productivity.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content