This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you’re diving into the world of machinelearning, AWS MachineLearning provides a robust and accessible platform to turn your data science dreams into reality. Introduction Machinelearning can seem overwhelming at first – from choosing the right algorithms to setting up infrastructure.
Summary: Hydra simplifies process configuration in MachineLearning by dynamically managing parameters, organising configurations hierarchically, and enabling runtime overrides. As the global MachineLearning market, valued at USD 35.80 These issues can hinder experimentation, reproducibility, and workflow efficiency.
Machinelearning (ML) has become a critical component of many organizations’ digital transformation strategy. The answer lies in the data used to train these models and how that data is derived. The answer lies in the data used to train these models and how that data is derived.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. If you’re using a Retrieval Augmented Generation (RAG) system to provide context to your LLM, you can use your existing ML feature pipelines as context.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machinelearning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. It enables you to use an off-the-shelf model as is without involving machinelearning operations (MLOps) activity. The solution offers two TM retrieval modes for users to choose from: vector and document search.
However, they can’t generalize well to enterprise-specific questions because, to generate an answer, they rely on the public data they were exposed to during pre-training. However, the popular RAG design pattern with semantic search can’t answer all types of questions that are possible on documents.
Dataiku is an advanced analytics and machinelearning platform designed to democratize data science and foster collaboration across technical and non-technical teams. Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machinelearning models.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Analyze data using generative AI. Prepare data for machinelearning.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. When needed, the system can access an ODAP data warehouse to retrieve additional information.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machinelearning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Also, check the frequency and stability of updates and improvements to the tool.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
Photo by AltumCode on Unsplash As a data scientist, I used to struggle with experiments involving the training and fine-tuning of large deep-learning models. If you are conducting experiments in machinelearning, I believe this article will prove immensely beneficial. Inputs and outputs are sourced from the data catalog.
Summary: Data quality is a fundamental aspect of MachineLearning. Poor-quality data leads to biased and unreliable models, while high-quality data enables accurate predictions and insights. What is Data Quality in MachineLearning? What is Data Quality in MachineLearning?
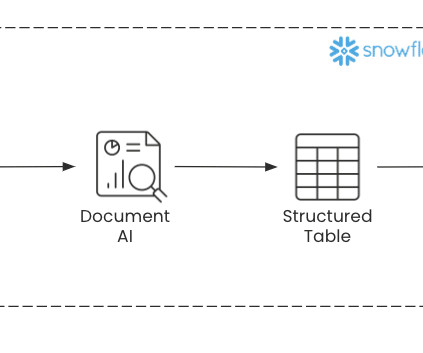
With an endless stream of documents that live on the internet and internally within organizations, the hardest challenge hasn’t been finding the information, it is taking the time to read, analyze, and extract it. What is Document AI from Snowflake? Document AI is a new Snowflake tool that ingests documents (e.g.,
However, applying version control to machinelearning (ML) pipelines comes with unique challenges. From data prep and model training to validation and deployment, each step is intricate and interconnected, demanding a robust system to manage it all. For example, see the documentation on Linting Python in Visual Studio.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machinelearning models relies on much more than selecting the best algorithm for the job. A primer on ML workflows and pipelines Before exploring the tools, we first need to explain the difference between ML workflows and pipelines.
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging.
To enable quick information retrieval, we use Amazon Kendra as the index for these documents. Amazon Kendra uses natural language processing (NLP) to understand user queries and find the most relevant documents. Grace Lang is an Associate Data & ML engineer with AWS Professional Services.
Machinelearning, particularly its subsets, deep learning, and generative ML, is currently in the spotlight. We are all still trying to figure out how to test machinelearning models. What is MachineLearning Model Testing? Evaluation Vs. Testing: Are They Different?
Machinelearning, particularly its subsets, deep learning, and generative ML, is currently in the spotlight. We are all still trying to figure out how to test machinelearning models. What is MachineLearning Model Testing? Evaluation Vs. Testing: Are They Different?
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Amazon Kendra is a fully managed service that provides out-of-the-box semantic search capabilities for state-of-the-art ranking of documents and passages. Amazon Kendra offers simple-to-use deep learning search models that are pre-trained on 14 domains and don’t require machinelearning (ML) expertise. Ask me a question.”
In today's data-driven world, machinelearning practitioners often face a critical yet underappreciated challenge: duplicate data management. A massive amount of diverse data powers today's ML models. You will find sections on managing duplicate data, best practices, current trends and so on.
With the help of the insights, we make further decisions on how to experiment and optimize the data for further application of algorithms for developing prediction or forecast models. What are ETL and datapipelines? These datapipelines are built by data engineers.
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides data science and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic data science concepts to advanced machinelearning techniques.
Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable. Tableau’s lightning-fast Google BigQuery connector allows customers to engineer optimized datapipelines with direct connections that power business-critical reporting. Direct connection to Google BigQuery.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. With every second on the track critical, the challenge showcased how data can shape decisions that define race outcomes.
The left side of the figure shows an example of a financial document as context, with the instruction asking the model to summarize the document. SGT release and deployment – The SGT that is output from the earlier optimization step is deployed as part of the datapipeline that feeds the trained LLM.
High-Quality Content : Curated data ensures relevance and minimises noise, enhancing model performance. Composition of the Pile Dataset The Pile dataset is an extensive and diverse text collection designed to fuel AI and MachineLearning advancements. It also features data from novels, legal documents, and medical texts.
Long-term ML project involves developing and sustaining applications or systems that leverage machinelearning models, algorithms, and techniques. However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams.
With sports (and everything else) cancelled, this data scientist decided to take on COVID-19 | A Winner’s Interview with David Mezzetti When his hobbies went on hiatus, Kaggler David Mezzetti made fighting COVID-19 his mission. Photo by Clay Banks on Unsplash Let’s learn about David! David, what can you tell us about your background?
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
As AI continues to advance at such an aggressive pace, solutions built on machinelearning are quickly becoming the new norm. Data scientists and data engineers want full control over every aspect of their machinelearning solutions and want coding interfaces so that they can use their favorite libraries and languages.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content