This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Code Interpreter ChatGPT Code Interpreter is a part of ChatGPT that allows you to run Python code in a live working environment. With Code Interpreter, you can perform tasks such as data analysis, visualization, coding, math, and more. You can also upload and download files to and from ChatGPT with this feature.
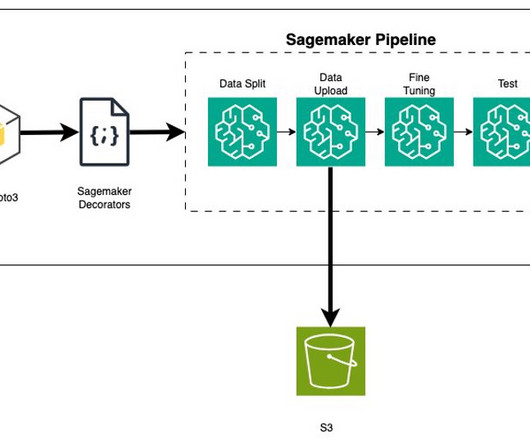
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Download Batch Inference Results: Download batch inference results after completing the batch inference job and message received by SQS. ?Create
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment?
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Download the free, unabridged version here. Automation Automating datapipelines and models ➡️ 6.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. In this blog, we’ll cover the steps to get started, including: How to set up an existing Snowpark project on your local system using a Python IDE.
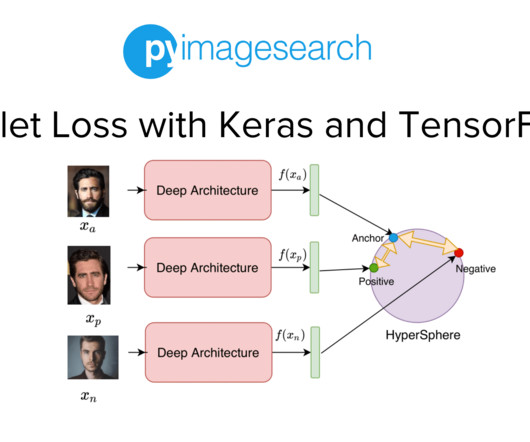
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The crop_faces.py
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
It comprises of four features, it is customizable, observable with a full view of data visualization, testable and versionable to track changes, and can easily be rolled back if needed. Modern stack : It is built using modern open-source technologies such as Python, Flask, and Vue.js, making it easy to extend and integrate with other tools.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources. We use Python to do this.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. For this reason, many DJL users also use it for inference only. With v0.21.0
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Monte Carlo Monte Carlo is a popular data observability platform that provides real-time monitoring and alerting for data quality issues. and Pandas or Apache Spark DataFrames.
Many ML systems benefit from having the feature store as their data platform, including: Interactive ML systems receive a user request and respond with a prediction. An interactive ML system either downloads a model and calls it directly or calls a model hosted in a model-serving infrastructure. All of them are written in Python.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Snowpark , an innovative technology from the Snowflake Data Cloud , promises to meet this demand by allowing data scientists to develop complex data transformation logic using familiar programming languages such as Java, Scala, and Python. Second, the performance of the inference logic easily and rapidly scales.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
When you think of the lifecycle of your data processes, Alteryx and Snowflake play different roles in a data stack. Alteryx provides the low-code intuitive user experience to build and automate datapipelines and analytics engineering transformation, while Snowflake can be part of the source or target data, depending on the situation.
Inside this folder, you’ll find the processed data files, which you can browse or download as needed. Access the output data using the AWS SDK Alternatively, you can access the processed data programmatically using the AWS SDK. decode('utf-8') # Initialize a list output_data = [] # Process the JSON data.
Some industries rely not only on traditional data but also need data from sources such as security logs, IoT sensors, and web applications to provide the best customer experience. For example, before any video streaming services, users had to wait for videos or audio to get downloaded. pip install tensorflow== 2.7.1 !pip
Implementing Precision and Recall Calculations in Python Now that we have defined and segregated our samples into True Positives , True Negatives , False Positives , and False Negatives , let us try to use them to compute specific metrics to evaluate our model. label_pred !=1 1 ), and their ground-truth label was positive ( label_gt =1 ).
Jump Right To The Downloads Section CycleGAN: Unpaired Image-to-Image Translation (Part 3) In the first tutorial of this series on unpaired image-to-image translation, we introduced the CycleGAN model. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. Let us open the train.py
Libraries like NumPy in Python are capable of tensor manipulations, especially matrix multiplications, which are essential in linear algebra. Keras 3 supports various datapipelines , allowing flexibility in how data is fed into the models. pip install -q tf-nightly # needed for some data processing in keras-cv !pip
When building your Processing Docker image, don't place any data required by your container in these directories. In this example, all our code is inside the src directory FROM python:3.8 In this example, all our code is inside the src directory FROM python:3.8 More on this is discussed later. Below is a sample DOCKER file.
The Widespread Adoption of Open DataScience The use of open source data science tools has absolutely explodedwere talking a whopping 650% growth over the past five years. Additionally, a clear majority of current projects ( 85% to be exact) leverage open-source programming languages like Python and R rather than proprietary options.
We will understand the dataset and the datapipeline for our application and discuss the salient features of the NSL framework in detail. Finally, in the 4th part of the tutorial series, we will look at our application’s training and inference pipeline and implement these routines using the Keras and TensorFlow libraries.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Datapipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
The datapipelines can be scheduled as event-driven or be run at specific intervals the users choose. Below are some pictorial representations of simple ETL operations we used for data transformation. For that, we used another pipeline based on AWS Glue. For more information, please refer to this video.
Luckily, both TensorFlow and OpenCV are pip-installable: $ pip install tensorflow $ pip install opencv-contrib-python If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in minutes. In this tutorial, we will discuss the model.py
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. Top 10 Python Scripts for use in Matillion for Snowflake 1. The default value is Python3.
You can download the package using the following code. !pip Updating the datapipeline When updating a training pipeline, it can be helpful to follow a few best practices to ensure a smooth transition and minimize errors and deployment holdups. In order to monitor the model, you can use a platform like neptune.ai.
Datapipelines must seamlessly integrate new data at scale. Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources. You can build and manage an incremental datapipeline to update embeddings on Vectorstore at scale. Choose Create notebook.
We created a Python script, invoke_bedrock_agent.py, with which we invoke the agent for a given prompt. python invoke_bedrock_agent.py "What are the open claims?" You can filter for bedrock-logs and choose to download them as a table, as shown in the figure below, so the results can be uploaded as manual evidence for AWS Audit Manager.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content