This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction ETLpipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETLpipeline, and how ETL scripts or tasks can be scheduled using shell scripting. The post ETLPipeline using Shell Scripting | DataPipeline appeared first on Analytics Vidhya.
Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […]. The post Building an ETLDataPipeline Using Azure Data Factory appeared first on Analytics Vidhya.
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Also: How I Redesigned over 100 ETL into ELT DataPipelines; Where NLP is heading; Don’t Waste Time Building Your Data Science Network; Data Scientists: How to Sell Your Project and Yourself.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Amphi is a micro ETL designed for extracting, preparing and cleaning data from various sources and formats. Develop datapipelines and generate native Python code you can deploy anywhere.
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
ArticleVideos I will admit, AWS Data Wrangler has become my go-to package for developing extract, transform, and load (ETL) datapipelines and other day-to-day. The post Using AWS Data Wrangler with AWS Glue Job 2.0 appeared first on Analytics Vidhya.
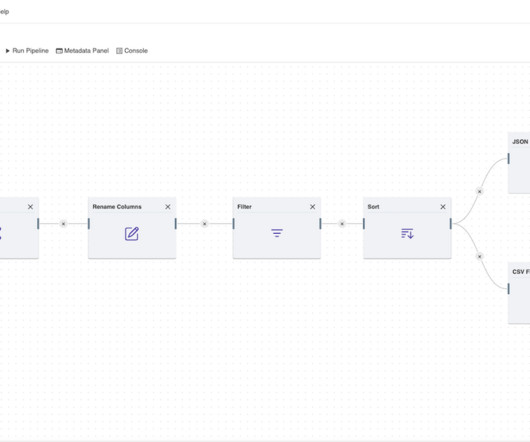
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Don’t Waste Time Building Your Data Science Network; 19 Data Science Project Ideas for Beginners; How I Redesigned over 100 ETL into ELT DataPipelines; Anecdotes from 11 Role Models in Machine Learning; The Ultimate Guide To Different Word Embedding Techniques In NLP.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow.
Also: How I Redesigned over 100 ETL into ELT DataPipelines; Where NLP is heading; Don’t Waste Time Building Your Data Science Network; Data Scientists: How to Sell Your Project and Yourself.
A datapipeline is a technical system that automates the flow of data from one source to another. While it has many benefits, an error in the pipeline can cause serious disruptions to your business. Here are some of the best practices for preventing errors in your datapipeline: 1. Monitor Your Data Sources.
Don’t Waste Time Building Your Data Science Network; 19 Data Science Project Ideas for Beginners; How I Redesigned over 100 ETL into ELT DataPipelines; Anecdotes from 11 Role Models in Machine Learning; The Ultimate Guide To Different Word Embedding Techniques In NLP.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build datapipelines to move data from Amazon Aurora to Amazon Redshift.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
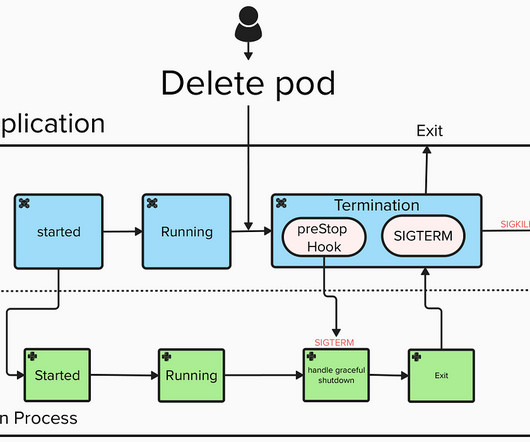
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
However, efficient use of ETLpipelines in ML can help make their life much easier. This article explores the importance of ETLpipelines in machine learning, a hands-on example of building ETLpipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Airflow: Apache Airflow is an open-source platform for orchestrating and scheduling datapipelines.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Datapipelines are like insurance. ETL processes are constantly toiling away behind the scenes, doing heavy lifting to connect the sources of data from the real world with the warehouses and lakes that make the data useful. You only know they exist when something goes wrong.
Those who want to design universal datapipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each datapipeline platform embodies a unique philosophy, architectural design, and set of operations.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
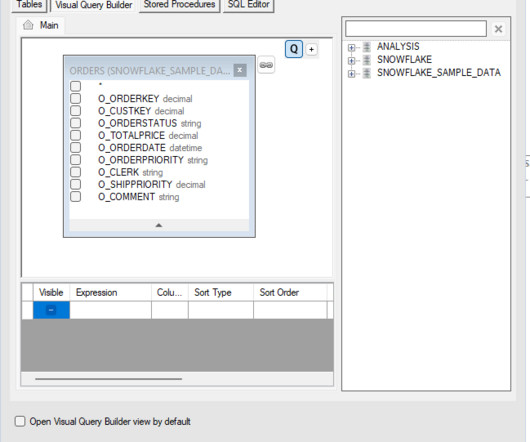
Matillion has a Git integration for Matillion ETL with Git repository providers, which your company can use to leverage your development across teams and establish a more reliable environment. In this blog, you will learn how to set up your Matillion ETL to be integrated with Azure DevOps and used as a Git repository for your developments.
In the data analytics processes, choosing the right tools is crucial for ensuring efficiency and scalability. Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETLpipeline orchestration. ETL ProcessBasics So what exactly is ETL? What is an Agent?
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Matillion has a Git integration for Matillion ETL with Git repository providers, which can be used by your company to leverage your development across teams and establish a more reliable environment. What is Matillion ETL? To start, we’ll use the URL of your new BitBucket repository to point to the Matillion ETL platform later.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content