This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The concept of streaming data was born of necessity. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Business success is based on how we use continuously changing data.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. The Batch job automatically launches an ML compute instance, deploys the model, and processes the input data in batches, producing the output predictions.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. Prompt 2: Were there any major world events in 2016 affecting the sale of Vegetables?
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Spark, Flink, etc.)
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. For more information, refer to Preview: Use Amazon SageMaker to Build, Train, and Deploy ML Models Using Geospatial Data.
Six core principles of a realtime streaming pipeline Drawing on Matus Tomleins stepbystep Implementation Guide: Building an AIReady DataPipeline Architecture , you can anchor any streaming stack around six nonnegotiables: Explicit data requirements. Tight ML integration. Schemafirst design. Duallayer storage.
Amazon Elastic Kubernetes Service (Amazon EKS) retrieves data from Amazon DocumentDB , processes it, and invokes Amazon Bedrock Agents for reasoning and analysis. This structured datapipeline enables optimized pricing strategies and multilingual customer interactions.
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
Lambda enables serverless, event-driven data processing tasks, allowing for real-time transformations and calculations as data arrives. Step Functions complements this by orchestrating complex workflows, coordinating multiple Lambda functions, and managing error handling for sophisticated data processing pipelines.
In this post we highlight how the AWS Generative AI Innovation Center collaborated with the AWS Professional Services and PGA TOUR to develop a prototype virtual assistant using Amazon Bedrock that could enable fans to extract information about any event, player, hole or shot level details in a seamless interactive manner.
AI systems, as well as the infrastructure in which they are deployed, are said to be resilient if they can withstand unexpected adverse events or unexpected changes in their environment or use. Datapipelines that ingest data to the knowledge base should account for throttling and use backoff techniques.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. Their task is to construct and oversee efficient datapipelines.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. Deploy the trained ML model to a SageMaker inference endpoint.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Let’s add some transformations to get our data ready for training an ML model.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Geobox enables city departments to do the following: Improved climate adaptation planning – Informed decisions reduce the impact of extreme heat events.
In these applications, time series data can have heavy-tailed distributions, where the tails represent extreme values. Accurate forecasting in these regions is important in determining how likely an extreme event is and whether to raise an alarm. However, the extreme event will have zero probability.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
Unleashing Innovation and Success: Comet — The Trusted ML Platform for Enterprise Environments Machine learning (ML) is a rapidly developing field, and businesses are increasingly depending on ML platforms to fuel innovation, improve efficiency, and mine data for insights.
Chronos is founded on a key insight: both LLMs and time series forecasting aim to decode sequential patterns to predict future events. This parallel allows us to treat time series data as a language to be modeled by off-the-shelf transformer architectures. In addition, he builds and deploys AI/ML models on the AWS Cloud.
Traditional maintenance activities rely on a sizable workforce distributed across key locations along the BHS dispatched by operators in the event of an operational fault. It’s an easy way to run analytics on IoT data to gain accurate insights. Motor 2 operated in a cooler environment, where the temperature was ranging between 20–25°C.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machine learning (ML) models. The architecture employs an event-driven model, where the completion of one snap triggers the next step in the workflow.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and MLPipelines. Building data and MLpipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? This will also help us observe the importance of stream data. It can be used to collect, store, and process streaming data in real-time.
Our planet sends distress signals through extreme weather events, melting ice caps, and vanishing species. Enter machine learning (ML) , the technological powerhouse that has revolutionized industries from healthcare to finance, with its unparalleled ability to analyze vast datasets, identify patterns, and make predictions.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). It can be used with both on-premise and multi-cloud environments.
With Composable ML , expert data scientists can extend DataRobot’s AutoML blueprints with their domain knowledge and custom code. Composable ML turns DataRobot blueprints into reusable building blocks. These retraining policies can be based on a schedule of your choosing or triggered by an event like data drift.
Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines. These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Serverless and function as a service (FaaS) In a serverless environment, function as a service (FaaS) —a service that allows customers to run code in response to events—is critical to freeing up developers from managing the underlying infrastructure. In a serverless model, an event triggers app code to run.
It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime. The post How Data Observability Helps to Build Trusted Data appeared first on Precisely.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions. You need to find a place to park your data.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions. You need to find a place to park your data.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
Monday’s sessions will cover a wide range of topics, from Generative AI and LLMs to MLOps and Data Visualization. Finally, get ready for some All Hallows Eve fun with Halloween Data After Dark , featuring a costume contest, candy, and more. There will also be an in-person career expo where you can find your next job in data science!
And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used. Scheduling.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















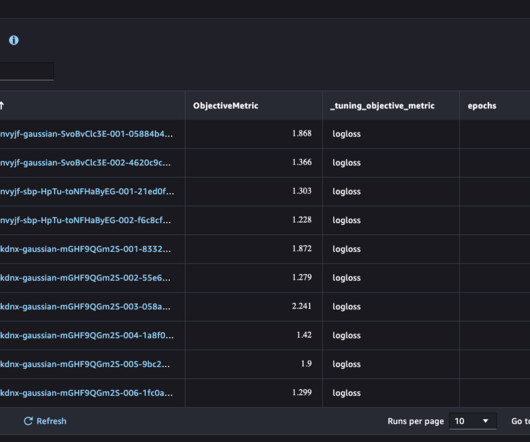







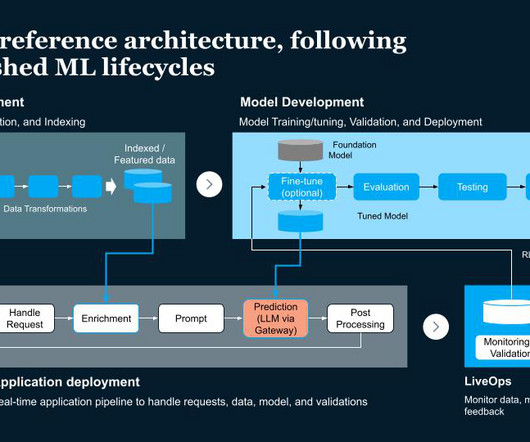




















Let's personalize your content