This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. Free to use. Conclusion There are a ton of small services that aren’t supported on traditional datapipeline platforms.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Let’s explore each of these components and its application in the sales domain: Synapse Data Engineering: Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse. Here, we changed the data types of columns and dealt with missing values.
Using structured data to answer questions requires a way to effectively extract data that’s relevant to a user’s query. We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. The SQL is run by Amazon Athena to return the relevant data.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
You can see our photos from the event here , and be sure to follow our YouTube for virtual highlights from the conference as well. We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and of course, plenty related to large language models and generative AI. What’s next?
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. Flink jobs, designed to process continuous data streams, are key to making this possible. They are able to adapt to changing demands quickly to seize new opportunities.
Over the last month, we’ve been heavily focused on adding additional support for SQL translations to our SQL Translations tool. Specifically, we’ve been introducing fixes and features for our Microsoft SQL Server to Snowflake translation. This is where the SQL Translation tool can be a massive accelerator for your migration.
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With Apache Kafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
We’ve been focusing on two key areas: Microsoft SQL Server to Snowflake Data Cloud SQL translations and our new Advisor tool within the phData Toolkit. Operational Risks identify operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Let’s dive in.
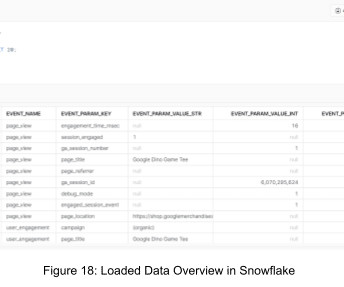
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw eventdata from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
It could help you detect and prevent datapipeline failures, data drift, and anomalies. Montecarlo offers data quality checks, profiling, and monitoring capabilities to ensure high-quality and reliable data for machine learning and analytics. Flyte Flyte is a platform for orchestrating ML pipelines at scale.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
In this blog, we will highlight some of the most important upcoming features and updates for those who could not attend the events, specifically around AI and developer tools. Snowflake Copilot, soon-to-be GA, allows technical users to convert questions into SQL. Furthermore, Snowflake Notebooks can also be run on a schedule.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Interested in attending an ODSC event?
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Migrating Your Pipelines and Code It’s more than likely that your business has years of code being used in its datapipelines. It is also a helpful tool for learning a new SQL dialect.
Furthermore, we’ve developed data encryption and governance solutions for HPCC Systems to help secure data, ensure it is only accessed by appropriate personnel, and to create audit trails to ensure data security SLAs and regulations are met. It truly is an all-in-one data lake solution. Tell me more about ECL.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. The most common example of such databases is where events are tracked.
The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. It even offers a user-friendly interface to visualize the pipelines and monitor progress. The Data Source Tool can automate scanning DDL and profiling tables between source and target, comparing them, and then reporting findings.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as Power BI and Tableau as well.
This evolved into the phData Toolkit , a collection of high-quality data applications to help you migrate, validate, optimize, and secure your data. Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Data warehousing is a vital constituent of any business intelligence operation. Simplify and Win Experienced data engineers value simplicity.
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Python : Great for including AI in Python-based software or datapipelines.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
For instance, differential privacy adds noise to query results as a means of preventing access to Personally Identifiable Information (PII) and running multi-party computations directly on encrypted data. Object Tagging Tags are schema-level objects that allow data stewards to monitor sensitive data for compliance, protection, or discovery.
However, a master’s degree or specialised Data Science or Machine Learning courses can give you a competitive edge, offering advanced knowledge and practical experience. Essential Technical Skills Technical proficiency is at the heart of an Azure Data Scientist’s role.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
What Are the Best Third-Party Data Ingestion Tools for Snowflake? Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.).
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
Datapipeline orchestration. Support for languages and SQL. Moving/integrating data in the cloud/data exploration and quality assessment. Supports the ability to interact with the actual data and perform analysis on it. Collaboration and governance. Low-code, no-code operation. Scheduling. Target Matching.
Data Quality Dimensions Data quality dimensions are the criteria that are used to evaluate and measure the quality of data. These include the following: Accuracy indicates how correctly data reflects the real-world entities or events it represents. It is SQL-based and integrates well with modern data warehouses.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. JV_STAGING_TBL} Here is what the outline of the pipeline looks like. 30 minutes).
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. Use Amazon Athena SQL queries to provide insights.
Monday’s sessions will cover a wide range of topics, from Generative AI and LLMs to MLOps and Data Visualization. Finally, get ready for some All Hallows Eve fun with Halloween Data After Dark , featuring a costume contest, candy, and more. There will also be an in-person career expo where you can find your next job in data science!
The service will consume the features in real time, generate predictions in near real-time , such as in an event processing pipeline, and write the outputs to a prediction queue. I have worked with customers where R and SQL were the first-class languages of their data science community.
Yet despite these rich capabilities, challenges stillarise The Fragmentation Challenge With so many modular open-source libraries and frameworks now available, effectively stitching together coherent data science application workflows poses a frequent headache for practitioners. So whats needed to smooth the path forward?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content