This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The Internet of Things(IoT) devices can generate a large […]. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. Only knowledge that is used sticks in your mind.-
Data warehouses contain historical information that has been cleared to suit a relational plan. On the other hand, data lakes store from an extensive array of sources like real-time social media streams, Internet of Things devices, web app transactions, and user data.
Recognizing the potential of data, organizations are trying to extract values from their data in various ways to create new revenue streams and reduce the cost and resources required for operations. The increased amounts and types of data, stored in various locations eventually made the management of data more challenging.
Producers and consumers A ‘producer’, in Apache Kafka architecture, is anything that can create data—for example a web server, application or application component, an Internet of Things (IoT) , device and many others. Here are a few of the most striking examples.
This pipeline facilitates the smooth, automated flow of information, preventing many problems that enterprises face, such as data corruption, conflict, and duplication of data entries. A streaming datapipeline is an enhanced version which is able to handle millions of events in real-time at scale. Happy Learning!
Additionally, serverless’ always-on capabilities mean datapipelines can be designed in a way to react to real-time changes in data and change application logic accordingly. Today, serverless helps developers build scalable big datapipelines without having to manage the underlying infrastructure.
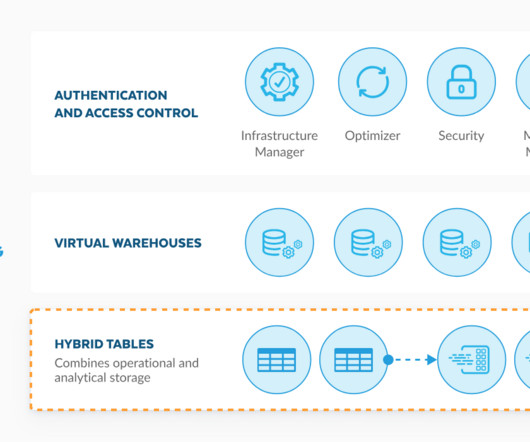
Internet of Things (IoT) Sensor Data: For ingesting and managing sensor data from IoT devices, Hybrid tables can handle the high volume of real-time updates while enabling historical analysis of sensor readings to identify trends or predict equipment failures.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of datapipelines. Its visual interface allows users to design complex ETL workflows with ease.
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment , AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges.
Today, data integration is moving closer to the edges – to the business people and to where the data actually exists – the Internet of Things (IoT) and the Cloud. 3) The emergence of a new enterprise information management platform.
These features, combined with user-friendly interfaces and robust security measures, make TSDBs a valuable asset for organisations looking to harness the power of their time series data. Security is Paramount Implement robust security measures to protect sensitive time series data.
But the most impactful developments may be those focused on governance, middleware, training techniques and datapipelines that make generative AI more trustworthy , sustainable and accessible, for enterprises and end users alike. Here are some important current AI trends to look out for in the coming year.
Discoveries and improvements across seed genetics, site-specific fertilizers, and molecule development for crop protection products have coincided with innovations in generative AI , Internet of Things (IoT) and integrated research and development trial data, and high-performance computing analytical services.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content