
Build a Serverless News Data Pipeline using ML on AWS Cloud
KDnuggets
NOVEMBER 18, 2021
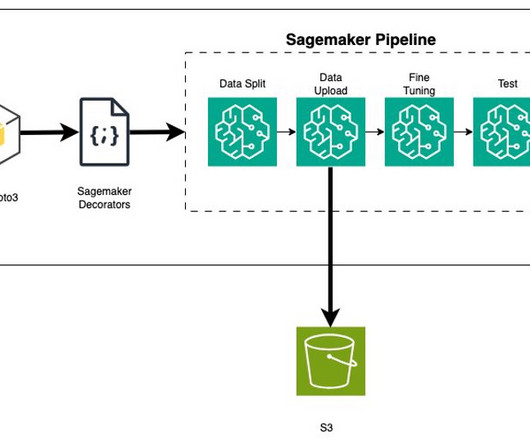
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

databricks
DECEMBER 12, 2023
Introduction Databricks Lakehouse Monitoring allows you to monitor all your data pipelines – from data to features to ML models – without additional too.

insideBIGDATA
JUNE 4, 2024
Modern data pipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.

AWS Machine Learning Blog
NOVEMBER 26, 2024
With the increasing use of large models, requiring a large number of accelerated compute instances, observability plays a critical role in ML operations, empowering you to improve performance, diagnose and fix failures, and optimize resource utilization. Anjali Thatte is a Product Manager at Datadog.

FEBRUARY 3, 2023
Over the last few years, with the rapid growth of data, pipeline, AI/ML, and analytics, DataOps has become a noteworthy piece of day-to-day business New-age technologies are almost entirely running the world today. Among these technologies, big data has gained significant traction. This concept is …

Precisely
DECEMBER 28, 2023
The concept of streaming data was born of necessity. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Business success is based on how we use continuously changing data.

Expert insights. Personalized for you.







































Let's personalize your content