Build a Serverless News Data Pipeline using ML on AWS Cloud
KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
 Data Pipeline ML Python
Data Pipeline ML Python 
KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Machine Learning Blog
MARCH 8, 2023
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.

NOVEMBER 24, 2023
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.

The MLOps Blog
MAY 17, 2023
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Towards AI
APRIL 4, 2023
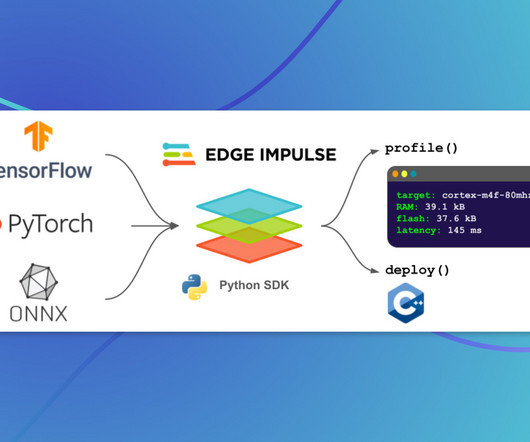
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices.

Dataconomy
MAY 16, 2023
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building data pipelines.

AWS Machine Learning Blog
AUGUST 12, 2024
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.

AUGUST 17, 2023
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select.

phData
AUGUST 6, 2024
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective data pipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.

Mlearning.ai
APRIL 6, 2023
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference data pipeline on large datasets is a challenge many companies face. The Batch job automatically launches an ML compute instance, deploys the model, and processes the input data in batches, producing the output predictions.

ODSC - Open Data Science
APRIL 23, 2025
AI credits from Confluent can be used to implement real-time data pipelines, monitor data flows, and run stream-based ML applications. Amazon Web Services(AWS) AWS offers one of the most extensive AI and ML infrastructures in the world. Modal Modal offers serverless compute tailored for data-intensive workloads.

Pickl AI
JULY 8, 2024
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
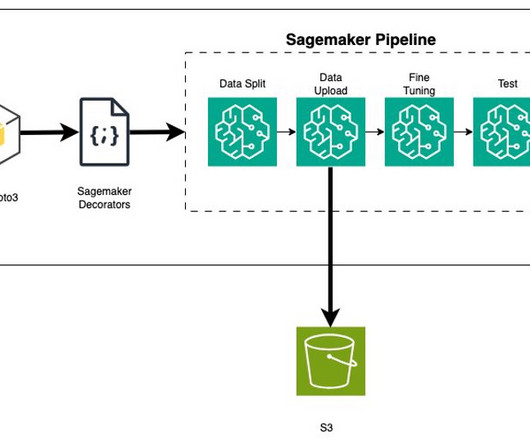
AWS Machine Learning Blog
AUGUST 22, 2024
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.

AWS Machine Learning Blog
JUNE 18, 2024
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).

Applied Data Science
AUGUST 2, 2021
Automation Automating data pipelines and models ➡️ 6. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. The Data Engineer Not everyone working on a data science project is a data scientist.

AWS Machine Learning Blog
APRIL 19, 2023
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. Business requirements We are the US squad of the Sportradar AI department.

The MLOps Blog
JUNE 27, 2023
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.

How to Learn Machine Learning
DECEMBER 24, 2024
You can easily: Store and process data using S3 and RedShift Create data pipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.

PyImageSearch
DECEMBER 18, 2023
This format made for a fast-paced and diverse showcase of ideas and applications in AI and ML. In just 3 minutes, each participant managed to highlight the core of their work, offering insights into the innovative ways in which AI and ML are being applied across various fields. But again, stick around for a surprise demo at the end. ?

Snorkel AI
MAY 26, 2023
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.

Snorkel AI
MAY 26, 2023
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.

AWS Machine Learning Blog
MARCH 1, 2023
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.

Pickl AI
NOVEMBER 29, 2024
It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation. This blog highlights the importance of organised, flexible configurations in ML workflows and introduces Hydra. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale data pipelines.

Heartbeat
NOVEMBER 6, 2023
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex data pipelines.

AWS Machine Learning Blog
SEPTEMBER 18, 2023
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.

phData
MARCH 22, 2023
As companies continue to adopt machine learning (ML) in their workflows, the demand for scalable and efficient tools has increased. In this blog post, we will explore the performance benefits of Snowpark for ML workloads and how it can help businesses make better use of their data. Total': (t_write - t_start).total_seconds()

The MLOps Blog
AUGUST 4, 2023
Situations described above arise way too often in ML teams, and their consequences vary from a single developer’s annoyance to the team’s inability to ship their code as needed. Let’s dive into the world of monorepos, an architecture widely adopted in major tech companies like Google, and how they can enhance your ML workflows.

phData
JULY 2, 2024
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. In this blog, we’ll cover the steps to get started, including: How to set up an existing Snowpark project on your local system using a Python IDE.

AWS Machine Learning Blog
APRIL 5, 2024
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. A grid system is established with a 48-meter grid size using Mapbox’s Supermercado Python library at zoom level 19, enabling precise spatial analysis.

ODSC - Open Data Science
FEBRUARY 17, 2023
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.

ODSC - Open Data Science
FEBRUARY 24, 2023
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. This tool automatically detects problems in an ML dataset.

DagsHub
AUGUST 29, 2024
Source: Author Introduction Machine learning (ML) models, like other software, are constantly changing and evolving. Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects.

Iguazio
JANUARY 16, 2024
Since AI is a central pillar of their value offering, Sense has invested heavily in a robust engineering organization including a large number of data and AI professionals. This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. Gennaro Frazzingaro, Head of AI/ML at Sense.

Towards AI
MAY 30, 2024
Prime_otter_86438 is working on a Python library to make ML training and running models on any microcontroller in real time for classification easy for beginners. They are seeking assistance from an expert to improve the model and make the Python package easier for the end user.

Iguazio
JANUARY 16, 2024
This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. The AI/Ml team is made up of ML engineers, data scientists and backend product engineers. With Iguazio, Sense’s data professionals can pull data, analyze it, train and run experiments.

AWS Machine Learning Blog
SEPTEMBER 18, 2024
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.

ODSC - Open Data Science
FEBRUARY 2, 2023
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. While knowing Python, R, and SQL are expected, you’ll need to go beyond that.

The MLOps Blog
JANUARY 26, 2024
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?

AWS Machine Learning Blog
OCTOBER 18, 2023
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.

AWS Machine Learning Blog
FEBRUARY 21, 2025
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.

The MLOps Blog
MARCH 15, 2023
In this post, you will learn about the 10 best data pipeline tools, their pros, cons, and pricing. A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
BAIR
FEBRUARY 17, 2024
Python code that calls an LLM), or should it be driven by an AI model (e.g. Likewise, in a compound system, where should a developer invest resources—for example, in a RAG pipeline, is it better to spend more FLOPS on the retriever or the LLM, or even to call an LLM multiple times? LLM agents that call external tools)?

The MLOps Blog
JANUARY 23, 2023
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Data pipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.

Expert insights. Personalized for you.
We have resent the email to
Are you sure you want to cancel your subscriptions?





Let's personalize your content