This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
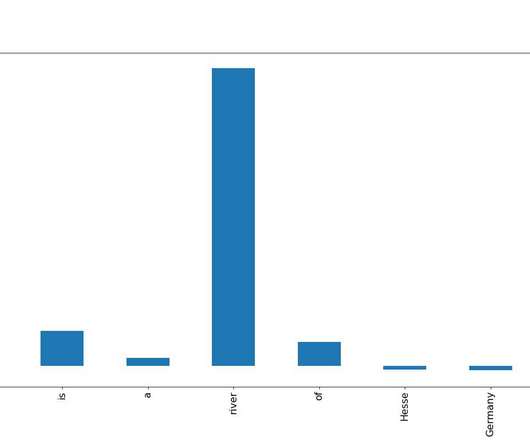
As the world becomes more interconnected and data-driven, the demand for real-time applications has never been higher. Artificial intelligence (AI) and naturallanguageprocessing (NLP) technologies are evolving rapidly to manage live data streams.
GenAI can help by automatically clustering similar data points and inferring labels from unlabeled data, obtaining valuable insights from previously unusable sources. NaturalLanguageProcessing (NLP) is an example of where traditional methods can struggle with complex text data.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground.
Data Engineering for Large Language Models LLMs are artificial intelligence models that are trained on massive datasets of text and code. They are used for a variety of tasks, such as naturallanguageprocessing, machine translation, and summarization.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Its diverse content includes academic papers, web data, books, and code. Frequently Asked Questions What is the Pile dataset?
We borrow proven techniques from the latest in NLP (naturallanguageprocessing) academia to build evaluation tooling that any software engineer can use. Devs shouldn’t be neck-deep in evaluation pipelines just to test their software, so we solve that complexity for them. What’s your secret sauce?
Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
It uses machine learning and naturallanguageprocessing technology to improve data matching. The reusability feature will help in data management and analytics, further maintaining the datapipeline. With the help of explainability, businesses can easily understand what the output would be.
Automation Automating datapipelines and models ➡️ 6. First, let’s explore the key attributes of each role: The Data Scientist Data scientists have a wealth of practical expertise building AI systems for a range of applications. The Data Engineer Not everyone working on a data science project is a data scientist.
Naturallanguageprocessing (NLP) engineer Potential pay range – US$164,000 to 267,000/yr As the name suggests, these professionals specialize in building systems for processing human language, like large language models (LLMs).
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processingdata. They use their knowledge of data warehousing, data lakes, and big data technologies to build and maintain datapipelines.
Amazon Kendra uses naturallanguageprocessing (NLP) to understand user queries and find the most relevant documents. For our final structured and unstructured datapipeline, we observe Anthropic’s Claude 2 on Amazon Bedrock generated better overall results for our final datapipeline.
Apart from supporting explanations for tabular data, Clarify also supports explainability for both computer vision (CV) and naturallanguageprocessing (NLP) using the same SHAP algorithm. Solution overview SageMaker algorithms have fixed input and output data formats.
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Artificial Intelligence : Concepts of AI include neural networks, naturallanguageprocessing (NLP), and reinforcement learning.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
In this post, Reveal experts showcase how they used Amazon Comprehend in their document processingpipeline to detect and redact individual pieces of PII. Amazon Comprehend is a fully managed and continuously trained naturallanguageprocessing (NLP) service that can extract insight about the content of a document or text.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. The process includes activities such as anomaly detection, event correlation, predictive analytics, automated root cause analysis and naturallanguageprocessing (NLP).
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. This allows you to control which IAM principals are allowed to decrypt the data and view it. For testing, choose yes.
Key Takeaways Data quality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Data observability continuously monitors datapipelines and alerts you to errors and anomalies.
He builds machine learning pipelines and recommendation systems for product recommendations on the Detail Page. Maria Masood specializes in building datapipelines and data visualizations at AWS Commerce Platform. Outside of work, he enjoys game development and rock climbing.
Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
From state-of-the-art language models to innovative AI-driven applications, to new open-source models hoping to take away GPT’s crown, let’s take a tour of some of the most notable AI tools and top LLMs that are working to shape how 2024 concludes, and how AI will shape the future.
Cortex offers a collection of ready-to-use models for common use cases, with capabilities broken into two categories: Cortex LLM functions provide Generative AI capabilities for naturallanguageprocessing, including completion (prompting) , translation, summarization, sentiment analysis , and vector embeddings.
We developed a custom datapipeline to handle the immense volume of visual data, resulting in significant cost savings and reduced human exposure to hazardous environments. This unprecedented project in Malaysia required creating robust models to identify defects in diverse industrial equipment under varying conditions.
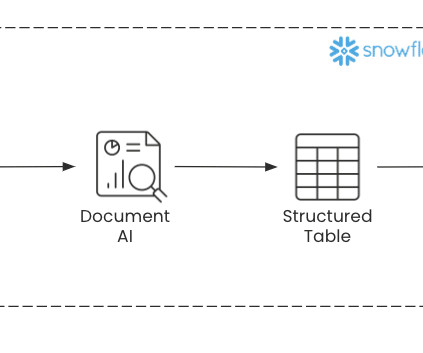
Datapipelines can be set up in Snowflake using stages , streams, and tasks to automate the continuous process of uploading documents, extracting information, and loading them into destination tables. Large Language Models Snowflake Document AI is powered by a first-party Large Language Model (LLM).
It has intuitive helpers and utilities for modalities like computer vision, naturallanguageprocessing, audio, time series, and tabular data. About the authors Fred Wu is a Senior Data Engineer at Sportradar, where he leads infrastructure, DevOps, and data engineering efforts for various NBA and NFL products.
By using the naturallanguageprocessing and generation capabilities of generative AI, the chat assistant can understand user queries, retrieve relevant information from various data sources, and provide tailored, contextual responses. Mohamed Mohamud is a Partner Solutions Architect with a focus on Data Analytics.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
A startup food manufacturer was utilizing social media data to track trends and find niche markets for developing new products. The marketing team spent weeks analyzing spreadsheets of TikTok and Twitter data. The Results The manufacturer quickly released two new product lines to capitalize on growing food trends.
Once an organization has identified its AI use cases , data scientists informally explore methodologies and solutions relevant to the business’s needs in the hunt for proofs of concept. These might include—but are not limited to—deep learning, image recognition and naturallanguageprocessing.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and naturallanguageprocessing (NLP) tasks since 2010. Inside the frontend/streamlit-ui folder, run bash run-streamlit-ui.sh.
Cutting-Edge Topics for EveryInterest Unlike many other AI bootcamps, ODSC East is designed to cover a wide range of trending topics in data science, ensuring theres something for everyone. We also place a heavy emphasis on the biggest topics in AI like LLMs, RAG, AI agents, and other things defining todays AI landscape.
Data professionals such as data engineers, data scientists, data analysts and data stewards benefit from these self-service data catalog tools that allow for self-service analytics, data discovery, and metadata management.
NaturalLanguageProcessing (NLP) has emerged as a dominant area, with tasks like sentiment analysis, machine translation, and chatbot development leading the way. Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus.
DL is particularly effective in processing large amounts of unstructured data, such as images, audio, and text. NaturalLanguageProcessing (NLP) : NLP is a branch of AI that deals with the interaction between computers and human languages.
This is achieved by using the pipeline to transfer data from a Splunk index into an S3 bucket, where it will be cataloged. The approach is shown in the following diagram. In this example, we use the service to classify whether a patient is likely to be admitted to a hospital over the next 30 days based on the combined dataset.
How to use ML to automate the refining process into a cyclical ML process. MLOps vs. AIOps AIOps , or artificial intelligence for IT operations, uses AI capabilities, such as naturallanguageprocessing and ML models, to automate and streamline operational workflows. How MLOps will be used within the organization.
The constant evolution of artificial intelligence has opened up exciting new perspectives in the field of naturallanguageprocessing (NLP). At the heart of this technological revolution are Large Language Models (LLMs), deep learning models capable of understanding and generating text remarkably smoothly and accurately.
Integrating naturallanguageprocessing capabilities allows for more human-like interactions, enhancing the overall fan experience. Check out this eye-opening story of how the Denver Broncos leveraged a Fan 360 approach to please fans and consistently sell out tickets with efficient data insights.
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.”
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.”
And with interfaces potentially ranging from SQL editors to naturallanguageprocessing, self-service for all may require a chameleon or suite of solutions to suit the individual. Regardless, all variations require the foundational data to be: Discoverable. The interface adapts to the unique needs of the persona.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































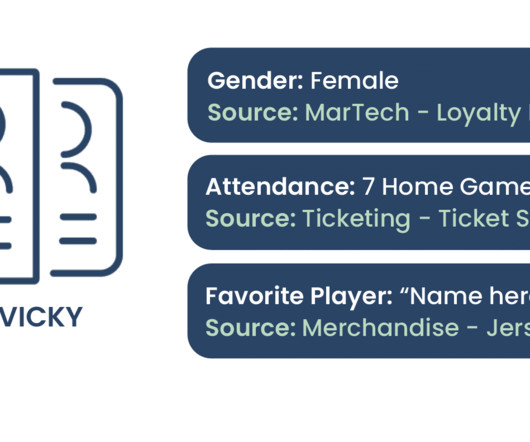









Let's personalize your content