This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Let’s explore each of these components and its application in the sales domain: Synapse Data Engineering: Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse. Here, we changed the data types of columns and dealt with missing values.
How to Optimize PowerBI and Snowflake for Advanced Analytics Spencer Baucke May 25, 2023 The world of business intelligence and data modernization has never been more competitive than it is today. Table of Contents Why Discuss Snowflake & PowerBI?
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. With the help of the model many insights can be drawn, and they can be visualized using software like PowerBI.
Key Features Tailored for Data Science These platforms offer specialised features to enhance productivity. Managed services like AWS Lambda and Azure Data Factory streamline datapipeline creation, while pre-built ML models in GCPs AI Hub reduce development time. Below are key strategies for achieving this.
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
R : Often used for statistical analysis and data visualization. Data Visualization : Techniques and tools to create visual representations of data to communicate insights effectively. Tools like Tableau, PowerBI, and Python libraries such as Matplotlib and Seaborn are commonly taught.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Excel, Tableau, PowerBI, SQL Server, MySQL, Google Analytics, etc.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model.
Data Engineering Career: Unleashing The True Potential of Data Problem-Solving Skills Data Engineers are required to possess strong analytical and problem-solving skills to navigate complex data challenges. Familiarize with data visualization techniques and tools like Matplotlib, Seaborn, Tableau, or PowerBI.
Determine How To Fill Gaps: Once you have identified any gaps in your data, determine how you can fill those gaps. You might need to build new datapipelines , purchase data from a third party, or simply transform your existing data to be more purposeful for business needs.
Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as PowerBI and Tableau as well. Machine Learning Engineer Machine learning engineers will use data much differently than business analysts or data analysts.
The software you might use OAuth with includes: Tableau PowerBI Sigma Computing If so, you will need an OAuth provider like Okta, Microsoft Azure AD, Ping Identity PingFederate, or a Custom OAuth 2.0 Datapipelines can be built with third-party tools alone or in conjunction with Snowflake’s tools. authorization server.
This includes important stages such as feature engineering, model development, datapipeline construction, and data deployment. For instance, feature engineering and exploratory data analysis (EDA) often require the use of visualization libraries like Matplotlib and Seaborn.
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling.
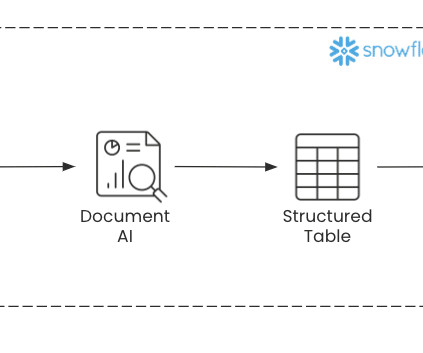
Datapipelines can be set up in Snowflake using stages , streams, and tasks to automate the continuous process of uploading documents, extracting information, and loading them into destination tables. Before diving into the technology that powers Document AI, let’s go over some of the utility that extracting your information offers.
Step 2: Analyze the Data Once you have centralized your data, use a business intelligence tool like Sigma Computing , PowerBI , Tableau , or another to craft analytics dashboards. It also leads to more company-wide collaboration and cuts unnecessary organizational expenses.
Business Intelligence Tools: Business intelligence (BI) tools are used to visualize your data. You should pick those that allow for easy integration and can create beautiful data visualizations. Examples of BI tools include Looker, PowerBI , and Tableau. You can also create documentation or video tutorials.
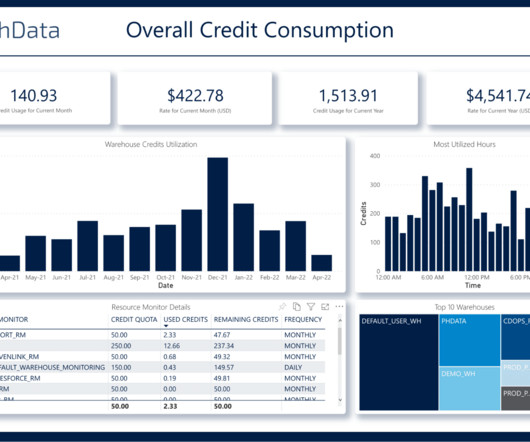
Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization: Locate and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
Apache Nifi Apache Nifi is an open-source ETL tool that automates data flow between systems. It is well known for its data provenance and seamless data routing capabilities. Nifi provides a graphical interface for designing datapipelines , allowing users to track data flows in real-time.
Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus. Tools like Apache Airflow are widely used for scheduling and monitoring workflows, while Apache Spark dominates big datapipelines due to its speed and scalability.
Azure Synapse Analytics Previously known as Azure SQL Data Warehouse , Azure Synapse Analytics offers a limitless analytics service that combines big data and data warehousing. This service enables Data Scientists to query data on their terms using serverless or provisioned resources at scale.
This oftentimes leads to shadow IT processes and duplicated datapipelines. Data is siloed, and there is no singular source of truth but fragmented data spread across the organization. Establishing a data culture changes this paradigm. The business will find other means to answer their questions.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Data Engineerings SteadyGrowth 20182021: Data engineering was often mentioned but overshadowed by modeling advancements. 20222024: As AI models required larger and cleaner datasets, interest in datapipelines, ETL frameworks, and real-time data processing surged.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content