

A Simple Data Pipeline to Show Use of Python Iterator
Analytics Vidhya
APRIL 4, 2022
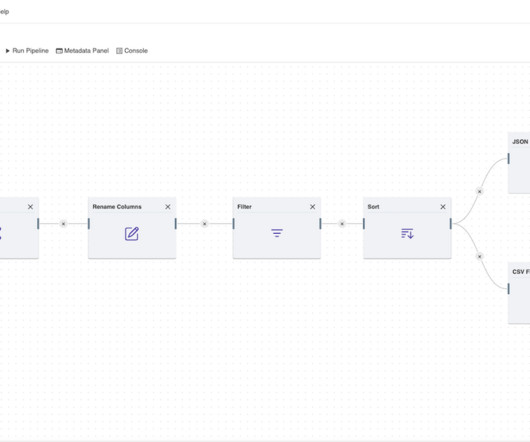
Introduction In this blog, we will explore one interesting aspect of the pandas read_csv function, the Python Iterator parameter, which can be used to read relatively large input data. Pandas library in python is an excellent choice for reading and manipulating data as data frames. […].















































Let's personalize your content