This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-qualitydata into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
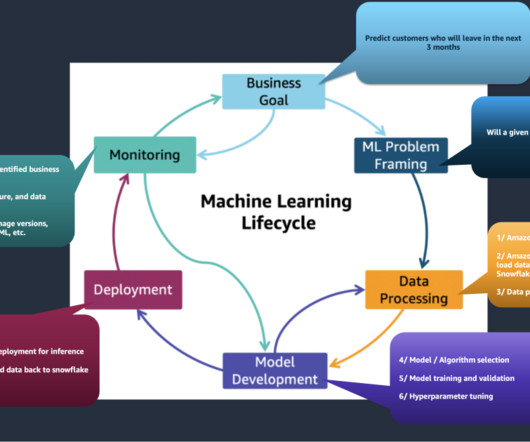
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Select the SQL (Create a dynamic view of data)Tile Explanation: This feature allows users to generate dynamic SQL queries for specific segments without manualcoding. Choose Segment ColumnData Explanation: Segmenting column dataprepares the system to generate SQL queries for distinctvalues.
Next Generation DataStage on Cloud Pak for Data Ensuring high-qualitydata A crucial aspect of downstream consumption is dataquality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? Given that data has higher stakes , it only means that you should invest most of your development investment in improving your dataquality.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Ensuring high-qualitydata A crucial aspect of downstream consumption is dataquality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis.
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Qualitydata is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. billion INR by 2026, with a CAGR of 27.7%. billion INR by 2027.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Limitations: Bias and interpretability: Machine learning algorithms may reflect biases present in the data used to train them, and it may be challenging to interpret how they arrived at their decisions. On the other hand, ML requires a significant amount of datapreparation and model training before it can be deployed.
Data Lakes compared to Data Warehouses – two different approaches What a data lake is not also helps to define it. Users: data scientists vs business professionals People who are not used to working with raw data frequently find it challenging to explore data lakes.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Metaflow Docs.
Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Data Wrangler creates the report from the sampled data.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and datascience experience who wanted to implement MLOps. Join thousands of data leaders on the AI newsletter.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing dataquality.
Increased operational efficiency benefits Reduced datapreparation time : OLAP datapreparation capabilities streamline data analysis processes, saving time and resources. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
Limitations: Bias and interpretability: Machine learning algorithms may reflect biases present in the data used to train them, and it may be challenging to interpret how they arrived at their decisions. On the other hand, ML requires a significant amount of datapreparation and model training before it can be deployed.
Data privacy policy: We all have sensitive data—we need policy and guidelines if and when users access and share sensitive data. Dataquality: Gone are the days of “data is data, and we just need more.” Now, dataquality matters. Data modeling. Data migration .
Ensuring dataquality, governance, and security may slow down or stall ML projects. Data engineering – Identifies the data sources, sets up data ingestion and pipelines, and preparesdata using Data Wrangler. Conduct exploratory analysis and datapreparation.
Evaluate the computing resources and development environment that the datascience team will need. Large projects or those involving text, images, or streaming data may need specialized infrastructure. Exploring and Transforming Data. Perform dataquality checks and develop procedures for handling issues.
Data privacy policy: We all have sensitive data—we need policy and guidelines if and when users access and share sensitive data. Dataquality: Gone are the days of “data is data, and we just need more.” Now, dataquality matters. Data modeling. Data migration .
Guided Navigation – Guided navigation provides intelligent suggestions, which guide correct usage of data. Behavioral intelligence, embedded in the catalog, learns from user behavior to enforce best practices through features like dataquality flags, which help folks stay compliant as they use data.
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
This blog discusses best practices, real-world use cases, security and privacy considerations, and how Data Scientists can use ChatGPT to their full potential. Machine Learning Models: How Data Scientists Use ChatGPT Data Scientists use ChatGPT as a powerful ally in the ever-evolving field of DataScience.
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Runs are executions of some piece of datascience code and record metadata and generated artifacts.
The datascience team expected an AI-based automated image annotation workflow to speed up a time-consuming labeling process. Enable a datascience team to manage a family of classic ML models for benchmarking statistics across multiple medical units.
Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building. These activities play a crucial role in extracting meaningful insights from raw data and improving model performance, leading to more robust and insightful results.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
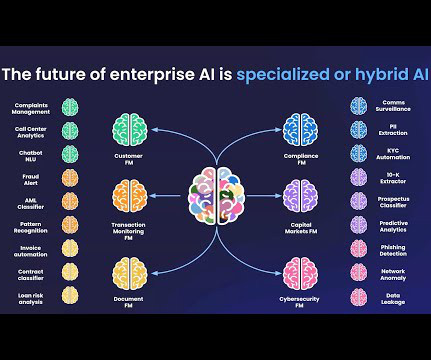
To achieve the trust, quality, and reliability necessary for production applications, enterprise datascience teams must develop proprietary data for use with specialized models. Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way.
Data manipulation in DataScience is the fundamental process in data analysis. The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis.
By maintaining clean and reliable data, businesses can avoid costly mistakes, enhance operational efficiency, and gain a competitive edge in their respective industries. Best Data Hygiene Tools & Software Trifacta Wrangler Pros: User-friendly interface with drag-and-drop functionality. Provides real-time data monitoring and alerts.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. The right tool can significantly enhance efficiency, scalability, and dataquality.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality. Why is ETL Important for Businesses?
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Data Engineering plays a critical role in enabling organizations to efficiently collect, store, process, and analyze large volumes of data. It is a field of expertise within the broader domain of data management and DataScience. Best Data Engineering Books for Beginners 1.
We use a test datapreparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model.
To achieve the trust, quality, and reliability necessary for production applications, enterprise datascience teams must develop proprietary data for use with specialized models. Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way.
The data value chain goes all the way from data capture and collection to reporting and sharing of information and actionable insights. As data doesn’t differentiate between industries, different sectors go through the same stages to gain value from it. Click to learn more about author Helena Schwenk.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. However, generalizing feature engineering is challenging.
Common Challenges in DataPreparation One of the most common challenges when preparing UCI datasets is dealing with missing data. Missing values can arise for various reasons, such as errors during data collection or inconsistencies in reporting.
Data Transformation Transforming dataprepares it for Machine Learning models. Encoding categorical variables converts non-numeric data into a usable format for ML models, often using techniques like one-hot encoding. This process ensures the model can scale, remain efficient, and adapt to changing data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content