This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Generative AI (GenAI), specifically as it pertains to the public availability of large language models (LLMs), is a relatively new business tool, so it’s understandable that some might be skeptical of a technology that can generate professional documents or organize data instantly across multiple repositories.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
Document understanding Fine-tuning is particularly effective for extracting structured information from document images. This includes tasks like form field extraction, table data retrieval, and identifying key elements in invoices, receipts, or technical diagrams. When working with documents, note that Meta Llama 3.2
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. This allows for better monitoring and auditing.
Natural language processing (NLP): ML algorithms can be used to understand and interpret human language, enabling organizations to automate tasks such as customer support and document processing. On the other hand, ML requires a significant amount of datapreparation and model training before it can be deployed.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
However, LLMs alone lack access to company-specific data, necessitating a retriever to fetch relevant information from various sources (databases, documents, etc.). It details the challenges of handling large documents and datasets and the importance of re-ranking retrieved information to ensure relevance.
Inquire whether there is sufficient data to support machine learning. Document assumptions and risks to develop a risk management strategy. Exploring and Transforming Data. Good data curation and datapreparation leads to more practical, accurate model outcomes. Define project scope.
Low data discoverability: For example, Sales doesn’t know what data Marketing even has available, or vice versa—or the team simply can’t find the data when they need it. . Unclear change management process: There’s little or no formality around what happens when a data source changes. Now, dataquality matters.
Then, they can quickly profile data using Data Wrangler visual interface to evaluate dataquality, spot anomalies and missing or incorrect data, and get advice on how to deal with these problems. The prepare page will be loaded, allowing you to add various transformations and essential analysis to the dataset.
Low data discoverability: For example, Sales doesn’t know what data Marketing even has available, or vice versa—or the team simply can’t find the data when they need it. . Unclear change management process: There’s little or no formality around what happens when a data source changes. Now, dataquality matters.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Datapreparation For this example, you will use the South German Credit dataset open source dataset.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality.
At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets. This approach not only enhances the efficiency of datapreparation but also improves the accuracy and relevance of AI models.
Behavioral intelligence, embedded in the catalog, learns from user behavior to enforce best practices through features like dataquality flags, which help folks stay compliant as they use data. Active Governance – Active data governance creates usage-based assignments, which prioritize and delegate curation duties.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. The right tool can significantly enhance efficiency, scalability, and dataquality.
This practice vastly enhances the speed of my datapreparation for machine learning projects. This is the first one, where we look at some functions for dataquality checks, which are the initial steps I take in EDA. within each project folder. Let’s get started. print_only (bool): If True, only print out the shape.
Natural language processing (NLP): ML algorithms can be used to understand and interpret human language, enabling organizations to automate tasks such as customer support and document processing. On the other hand, ML requires a significant amount of datapreparation and model training before it can be deployed.
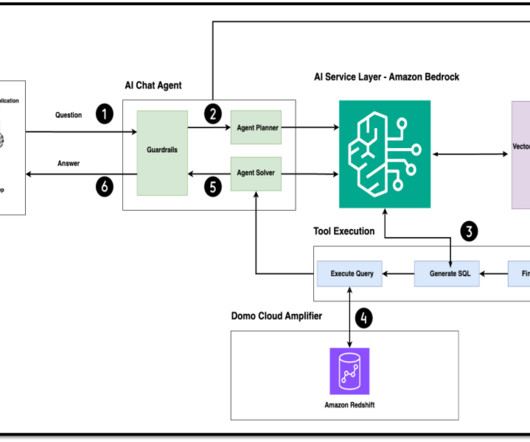
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis. powered by Amazon Bedrock Domo.AI
In the recent Gartner Peer Insights ‘Voice of the Customer’: DataPreparation Tools report , Tableau is the only vendor recognized in the Gartner Peer Insights Customers’ Choice distinction across all regions, company sizes, and industries—including the sole Customers’ Choice by users in the finance vertical. .
We use a test datapreparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model.
Important evaluation features include capabilities to preview a dataset, see all associated metadata, see user ratings, read user reviews and curator annotations, and view dataquality information. Figure 2 illustrates how analysis processes change when analysts work with a data catalog.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Data management is not yet a solved problem, but modern data management is leagues ahead of prior approaches. These include tracking, documenting, monitoring, versioning, and controlling access to AI/ML models. However, governance processes are equally important. Conclusion.
Preparing and organizing data into a format suitable for training models presents significant challenges for ML teams. Data cleaning complexity, dealing with diverse data types, and preprocessing large volumes of data consumes time and resources.
Data Management – Efficient data management is crucial for AI/ML platforms. Regulations in the healthcare industry call for especially rigorous data governance. It should include features like data versioning, data lineage, data governance, and dataquality assurance to ensure accurate and reliable results.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis. What is Data Manipulation? Data manipulation is crucial for several reasons.
Real-time processing is essential for applications requiring immediate data insights. Support : Are there resources available for troubleshooting, such as documentation, forums, or customer support? Security : Does the tool ensure data privacy and security during the ETL process?
Applications : Customer segmentation in marketing Identifying patterns in image recognition tasks Grouping similar documents or news articles for topic discovery Decision Trees Decision trees are non-parametric models that partition the data into subsets based on specific criteria. Datapreparation also involves feature engineering.
Data Transformation Transforming dataprepares it for Machine Learning models. Encoding categorical variables converts non-numeric data into a usable format for ML models, often using techniques like one-hot encoding. Outlier detection identifies extreme values that may skew results and can be removed or adjusted.
With these set up, you can move to the key LLMOps activities: Data Handling and Management - The organization, storage and pre-processing of the vast data needed for training language models. This includes versioning, ingestion and ensuring dataquality. Read more about implementing LLMOps in practice here. What is MLOps?
In the recent Gartner Peer Insights ‘Voice of the Customer’: DataPreparation Tools report , Tableau is the only vendor recognized in the Gartner Peer Insights Customers’ Choice distinction across all regions, company sizes, and industries—including the sole Customers’ Choice by users in the finance vertical. .
Data Scientists use data analysis plugins to automate and streamline data analysis tasks. Let’s examine some Data Analysis Plugins of ChatGPT. DataQuality Check: Plugins check the accuracy of data, identify mistakes, and suggest data cleaning procedures.
Source: Author SuperAnnotate helps annotate data with a wide range of tools like bounding boxes, polygons, and speech tagging. On top of that, it helps to manage teams, assign tasks, and ensure dataquality through collaborative annotation features. Offers advanced features for streamlined datapreparation and analysis.
The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Data ingestion (extraction and versioning). Data validation (writing tests to check for dataquality). Data preprocessing. Check out the documentation to get started.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content