This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machinelearning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes. Importance of qualitydata in fine-tuning Dataquality is paramount in the fine-tuning process.
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machinelearning (ML) and natural language processing (NLP), businesses can streamline their data analysis processes and make more informed decisions.
However, an expert in the field says that scaling AI solutions to handle the massive volume of data and real-time demands of large platforms presents a complex set of architectural, data management, and ethical challenges. One of the main challenges when scaling up is the inference of models in real-time, Krotkikh said.
Training-serving skew is a significant concern in the machinelearning domain, affecting the reliability of models in practical applications. Understanding how discrepancies between training data and operational data can impact model performance is essential for developing robust systems. What is training-serving skew?
Summary: Dataquality is a fundamental aspect of MachineLearning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in MachineLearning?
Presented by SQream The challenges of AI compound as it hurtles forward: demands of datapreparation, large data sets and dataquality, the time sink of long-running queries, batch processes and more. In this VB Spotlight, William Benton, principal product architect at NVIDIA, and others explain how …
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
The ability to quickly build and deploy machinelearning (ML) models is becoming increasingly important in today’s data-driven world. From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete.
Recently, we posted the first article recapping our recent machinelearning survey. There, we talked about some of the results, such as what programming languages machinelearning practitioners use, what frameworks they use, and what areas of the field they’re interested in. As the chart shows, two major themes emerged.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. Choose Data Wrangler in the navigation pane. For Analysis name , enter a name.
Introduction Machinelearning models learn patterns from data and leverage the learning, captured in the model weights, to make predictions on new, unseen data. Data, is therefore, essential to the quality and performance of machinelearning models.
With the increasing reliance on technology in our personal and professional lives, the volume of data generated daily is expected to grow. This rapid increase in data has created a need for ways to make sense of it all. Machinelearning is […].
This approach not only enhances the efficiency of datapreparation but also improves the accuracy and relevance of AI models. The SageMaker Jumpstart machinelearning hub offers a suite of tools for building, training, and deploying machinelearning models at scale.
On November 30, 2021, we announced the general availability of Amazon SageMaker Canvas , a visual point-and-click interface that enables business analysts to generate highly accurate machinelearning (ML) predictions without having to write a single line of code.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Inability to learn: RPA cannot learn from past experiences or adapt to new situations without human intervention. What is machinelearning (ML)?
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? MachineLearning is applied to an increasingly large number of applications that range from financial to healthcare industries.
Amazon SageMaker Canvas now empowers enterprises to harness the full potential of their data by enabling support of petabyte-scale datasets. Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset.
You can perform analytics with Data Lakes without moving your data to a different analytics system. 4. To comprehend and transform raw, unstructured data for any specific business use, it typically takes a data scientist and specialized tools. Data lakes therefore often need more storage space than data warehouses.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. An experiment collects multiple runs with the same objective. Madhubalasri B.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
In recent years, the field of machinelearning has gained tremendous momentum, offering powerful solutions and valuable insights from vast amounts of data. However, the process of building machinelearning models traditionally involved a time-consuming and resource-intensive approach, requiring extensive expertise.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Summary: The UCI MachineLearning Repository, established in 1987, is a crucial resource for MachineLearning practitioners. It supports various learning tasks, including classification and regression, and is organised by type and domain, facilitating easy access for users worldwide.
In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. We start from creating a data flow.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion by 2031, growing at a CAGR of 34.20%.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
In simple terms, data annotation helps the algorithms distinguish between what's important and what's not with the help of labels and annotations, allowing them to make informed decisions and predictions. Now you might be wondering, why exactly we need these annotation tools when we can label the ML data on our own.
The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machinelearning (ML) models in production reliably and efficiently. MLOps is the intersection of MachineLearning, DevOps, and Data Engineering. References [1] E. Russell and P.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machinelearning (ML), retail, and data and analytics. We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machinelearning (ML) workflows without writing any code.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
Although machinelearning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building.
How to Use MachineLearning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machinelearning were introduced.
Nonetheless, Data Scientists need to be mindful of its limitations and ethical issues. This blog discusses best practices, real-world use cases, security and privacy considerations, and how Data Scientists can use ChatGPT to their full potential. Data Scientists use data analysis plugins to automate and streamline data analysis tasks.
In the world of machinelearning (ML), the quality of the dataset is of significant importance to model predictability. Although more data is usually better, large datasets with a high number of features can sometimes lead to non-optimal model performance due to the curse of dimensionality. Choose Create.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and preparedata for machinelearning (ML) from weeks to minutes in Amazon SageMaker Studio. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Inability to learn: RPA cannot learn from past experiences or adapt to new situations without human intervention. What is machinelearning (ML)?
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machinelearning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
Do you need help to move your organization’s MachineLearning (ML) journey from pilot to production? Challenges Customers may face several challenges when implementing machinelearning (ML) solutions. Ensuring dataquality, governance, and security may slow down or stall ML projects. You’re not alone.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-language processing (NLP) service that uses machinelearning to uncover valuable insights and connections in text. This can increase user engagement.
For any machinelearning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
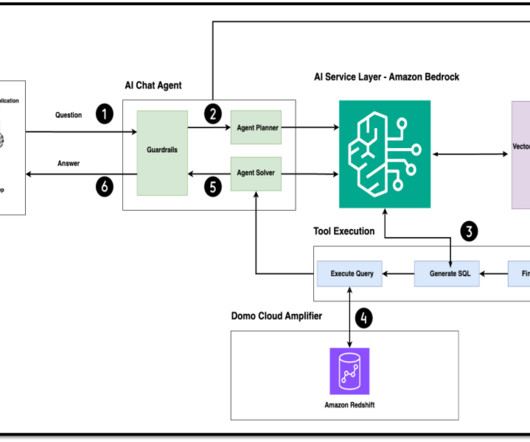
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis. powered by Amazon Bedrock Domo.AI
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content