This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machine learning (ML) and natural language processing (NLP), businesses can streamline their data analysis processes and make more informed decisions. What is augmented analytics?
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
He suggested that a Feature Store can help manage preprocessed data and facilitate cross-team usage, while a centralized Data Warehouse (DWH) domain can unify datapreparation and migration. From the data side, this is resolved through centralized datapreparation using a DWH (Data Warehouse) domain, Krotkikh said.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. This is where the AWS suite of low-code and no-code ML services becomes an essential tool.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. Custom Spark commands can also expand the over 300 built-in data transformations. We start from creating a data flow.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
This practice vastly enhances the speed of my datapreparation for machine learning projects. This is the first one, where we look at some functions for dataquality checks, which are the initial steps I take in EDA. within each project folder. Let’s get started.
On November 30, 2021, we announced the general availability of Amazon SageMaker Canvas , a visual point-and-click interface that enables business analysts to generate highly accurate machine learning (ML) predictions without having to write a single line of code. The key to scaling the use of ML is making it more accessible.
In part one of this series, I discussed how data management challenges have evolved and how data governance and security have to play in such challenges, with an eye to cloud migration and drift over time. Governing and Tracking ML/AI: The Rise of XAI. Many have heralded ML as a promising new frontier. Conclusion.
ML teams have a very important core purpose in their organizations - delivering high-quality, reliable models, fast. With users’ productivity in mind, at DagHub we aimed for a solution that will provide ML teams with the whole process out of the box and with no extra effort.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and preparedata for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Additional key topics Advanced metrics are not the only important tools available to you for evaluating and improving ML model performance.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Data Scientists and AI experts: Historically we have seen Data Scientists build and choose traditional ML models for their use cases. Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation. What percentage of machine learning models developed in your organization get deployed to a production environment?
The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering.
In the world of machine learning (ML), the quality of the dataset is of significant importance to model predictability. Although more data is usually better, large datasets with a high number of features can sometimes lead to non-optimal model performance due to the curse of dimensionality. For Target column , choose label.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machine learning were introduced.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
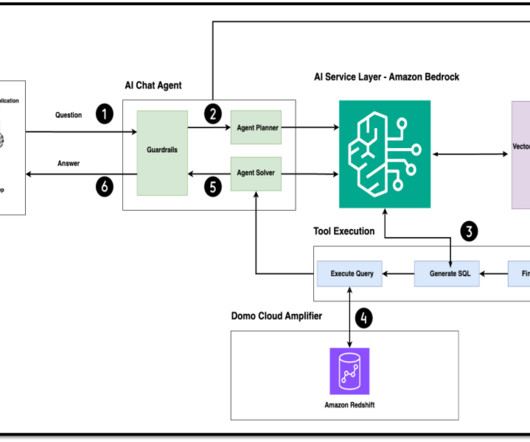
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis. powered by Amazon Bedrock Domo.AI
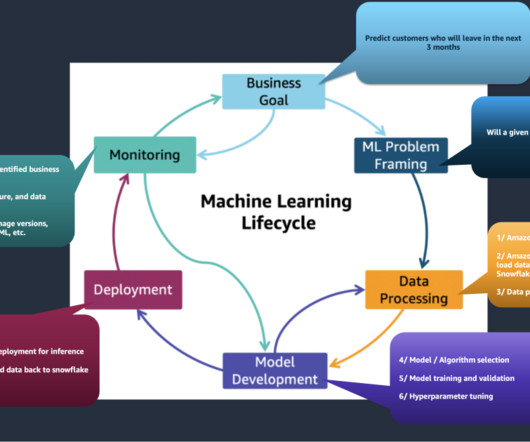
For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
There are many other features and functions , but to verify that a data catalog functions as platform, look for these five features: Intelligence – A data catalog should leverage AI/ML-driven pattern detection, including popularity, pattern matching, and provenance/impact analysis. Key Features of a Data Catalog.
Businesses face significant hurdles when preparingdata for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality. It also makes predictions for the future of ETL processes.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
They are characterized by their enormous size, complexity, and the vast amount of data they process. These elements need to be taken into consideration when managing, streamlining and deploying LLMs in ML pipelines, hence the specialized discipline of LLMOps. Data Pipeline - Manages and processes various data sources.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. You can find more details about training datapreparation and understand the custom classifier metrics.
Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
It follows a comprehensive, step-by-step process: Data Preprocessing: AutoML tools simplify the datapreparation stage by handling missing values, outliers, and data normalization. This ensures that the data is in the optimal format for model training. DataQuality: AutoML cannot compensate for poor dataquality.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content