This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machine learning (ML) and naturallanguageprocessing (NLP), businesses can streamline their data analysis processes and make more informed decisions.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. How can RPA improve dataquality and streamline data management processes?
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). Noise refers to random errors or irrelevant data points that can adversely affect the modeling process.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. How can RPA improve dataquality and streamline data management processes?
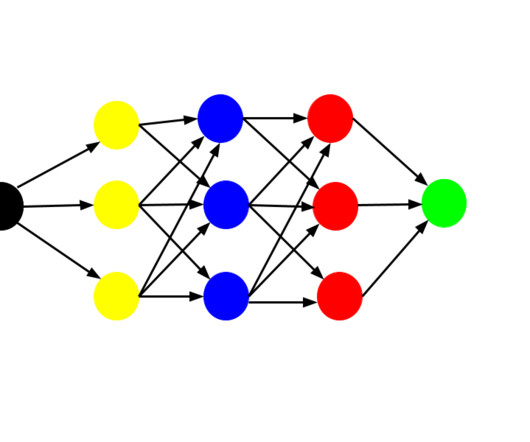
Neural networks are inspired by the structure of the human brain, and they are able to learn complex patterns in data. Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of naturallanguageprocessing, modeling, data analysis, data cleaning, and data visualization. Let’s examine some Data Analysis Plugins of ChatGPT.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. This can increase user engagement.
Large language models have emerged as ground-breaking technologies with revolutionary potential in the fast-developing fields of artificial intelligence (AI) and naturallanguageprocessing (NLP). Proper data management enables optimal LLM capacitive performance in language-centric AI applications.
Training a Convolutional Neural Networks Training a convolutional neural network (CNN) involves several steps: DataPreparation : This method entails gathering, cleaning, and preparing the data that will be utilized to train the CNN. The data should be split into training, validation, and testing sets.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. However, generalizing feature engineering is challenging.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, datapreparation, and algorithm selection. Dataquality significantly impacts model performance.
A strong data annotation tool should support you to annotate a variety of data formats, giving your machine learning projects flexibility and scalability. Accurate and thorough annotations require a tool that can handle many data sources, whether you're working with voice analysis, naturallanguageprocessing, or image identification.
These networks can learn from large volumes of data and are particularly effective in handling tasks such as image recognition and naturallanguageprocessing. Key Deep Learning models include: Convolutional Neural Networks (CNNs) CNNs are designed to process structured grid data, such as images.
After your generative AI workload environment has been secured, you can layer in AI/ML-specific features, such as Amazon SageMaker Data Wrangler to identify potential bias during datapreparation and Amazon SageMaker Clarify to detect bias in ML data and models.
The fine-tuning process The fine-tuning process generally involves several key steps, ensuring the model is adapted appropriately. Steps in fine-tuning a model Preprocessing data: Preparing specific datasets involves techniques that enhance dataquality for training, ensuring the model achieves optimal performance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












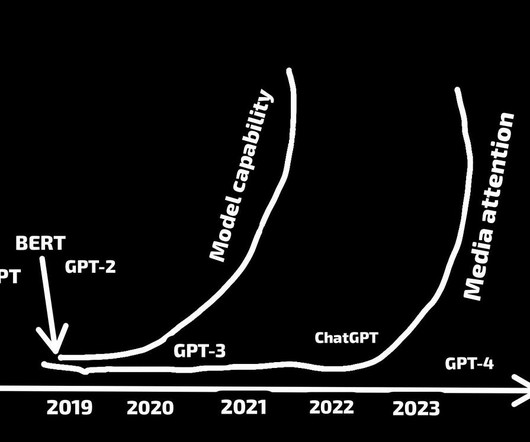











Let's personalize your content