This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Today’s question is, “What does a data scientist do.” ” Step into the realm of datascience, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of data scientists.
Pharmaceutical companies sell a variety of different, often novel, drugs on the market, where sometimes unintended but serious adverse events can occur. These events can be reported anywhere, from hospitals or at home, and must be responsibly and efficiently monitored. The training job is built using the SageMaker PyTorch estimator.
Unfortunately, our data engineering and machine learning ops teams haven’t built a feature vector for us, so all of the relevant data lives in a relational schema in separate tables. Understanding Relationships: GraphReduce doesn’t help with this part, so you’ll need to profile the data, talk to a data guru, or use emerging technology.
You can even use generative AI to supplement your data sets with synthetic data for privacy or accuracy. Most businesses already recognize the need to automate the actual analysis of data, but you can go further. Automating the datapreparation and interpretation phases will take much time and effort out of the equation, too.
Scalable Capital’s datascience and client service teams identified that one of the largest bottlenecks in servicing our clients was responding to email inquiries. The following diagram shows the workflow for our email classifier project, but can also be generalized to other datascience projects.
Demand forecasting, powered by datascience, helps predict customer needs. Optimize inventory, streamline operations, and make data-driven decisions for success. DataScience empowers businesses to leverage the power of data for accurate and insightful demand forecasts.
These statistical models are growing as a result of the wide swaths of available current data as well as the advent of capable artificial intelligence and machine learning. Data Sourcing. The applications of predictive analytics are extensive and often require four key components to maintain effectiveness.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Manager DataScience at Marubeni Power International. Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage. Because the data is being fetched hourly, a mechanism is also required to orchestrate and schedule ingestion jobs.
Here, we’ll discuss the key differences between AIOps and MLOps and how they each help teams and businesses address different IT and datascience challenges. Data characteristics and preprocessing AIOps tools handle a range of data sources and types, including system logs, performance metrics, network data and application events.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. With every second on the track critical, the challenge showcased how data can shape decisions that define race outcomes.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation.
Recent events including Tropical Cyclone Gabrielle have highlighted the susceptibility of the grid to extreme weather and emphasized the need for climate adaptation with resilient infrastructure. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
Unfortunately, even the datascience industry — which should recognize tabular data’s true value — often underestimates its relevance in AI. Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication.
The Women in Big Data (WiBD) Spring Hackathon 2024, organized by WiDS and led by WiBD’s Global Hackathon Director Rupa Gangatirkar , sponsored by Gilead Sciences, offered an exciting opportunity to sharpen datascience skills while addressing critical social impact challenges.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Going into developing machine learning models with a hands-on, data-centric AI approach has its benefits and requires a few extra steps to achieve. Here’s how to get there. Here are a few common mashups that may be right up your alley.
The datascience team expected an AI-based automated image annotation workflow to speed up a time-consuming labeling process. Enable a datascience team to manage a family of classic ML models for benchmarking statistics across multiple medical units.
A seamless user experience when deploying and monitoring DataRobot models to Snowflake Monitoring service health, drift, and accuracy of DataRobot models in Snowflake “Organizations are looking for mature datascience platforms that can scale to the size of their entire business. launch event on March 16th.
Businesses require Data Scientists to perform Data Mining processes and invoke valuable data insights using different software and tools. What is Data Mining and how is it related to DataScience ? What is Data Mining? Why is Data Mining Important? are the various data mining tools.
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
Most of these features also come with AI assistance to help users find the best way to visualize their data. One thing that sets it apart is Power BI’s ability to simplify the often complex and time-consuming task of datapreparation. Interested in attending an ODSC event? Learn more about our upcoming events here.
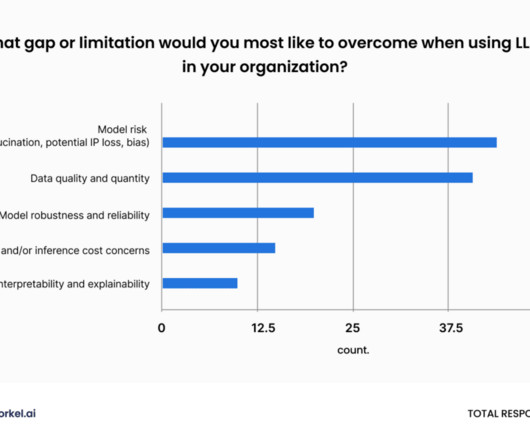
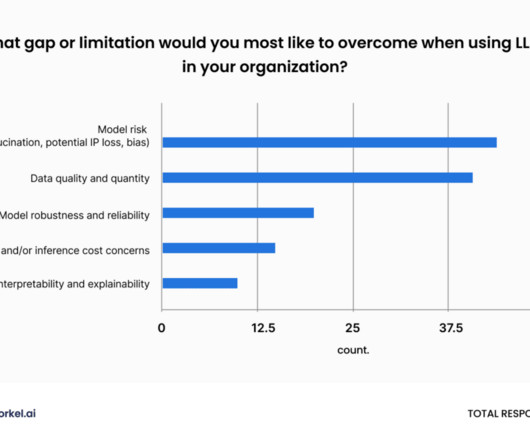
25 Enterprise LLM Summit: Building GenAI with Your Data drew over a thousand engaged attendees across three and a half hours and nine sessions. The eight speakers at the event—the second in our Enterprise LLM series—united around one theme: AI data development drives enterprise AI success. Snorkel AI’s Jan.
HPCC is a high-performance computing platform that helps organizations process and analyze large amounts of data. Qwak Qwak is a datascience platform that simplifies and accelerates the machine learning lifecycle. It provides a unified platform for datapreparation, model training, deployment, and monitoring.
First, we have data scientists who are in charge of creating and training machine learning models. They might also help with datapreparation and cleaning. The machine learning engineers are in charge of taking the models developed by data scientists and deploying them into production.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building. These activities play a crucial role in extracting meaningful insights from raw data and improving model performance, leading to more robust and insightful results.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Datascience / AI / ML leaders: Heads of DataScience, VPs of Advanced Analytics, AI Lead etc. The book contains a full chapter dedicated to generative AI. Key Takeaways 1.
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. Integration: Seamlessly integrates with popular DataScience tools and frameworks, such as TensorFlow and PyTorch.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
It was a crucial lesson in the power of using tangible, recent events to illustrate potential value. Tool choice may influence design, as each tool has preferred data structures, though corporate strategy and cost considerations may ultimately drive the decision. Future trends Emerging trends are reshaping the data analytics landscape.
And, for the tenth anniversary of ODSC East , we are pulling out all of the stops with new tracks, new events, and even a new location. Youll gain immediate, practical skills in Python, datapreparation, machine learning modeling, and retrieval-augmented generation (RAG), all leading up to AI Agents. Find outbelow!
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Metaflow Docs. neptune.ai
For example, location-based insights can be delivered through web GIS (geographic information systems) applications or datascience models. Enriched consumer data can shed light on the demographic makeup of a community, income levels, psychographics, lifestyle attributes, and more.
Time Complexity in Data Structures and Algorithms Data structures and algorithms are the building blocks of DataScience workflows. Sorting Algorithms Sorting algorithms play a crucial role in datapreparation. Searching Algorithms Efficient searching is essential for various DataScience tasks.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring. Matthew Chasse is a DataScience consultant at Amazon Web Services, where he helps customers build scalable machine learning solutions.
They design intricate sequences of prompts, leveraging their knowledge of AI, machine learning, and datascience to guide powerful LLMs (Large Language Models) towards complex tasks. Datascience methodologies and skills can be leveraged to design these experiments, analyze results, and iteratively improve prompt strategies.
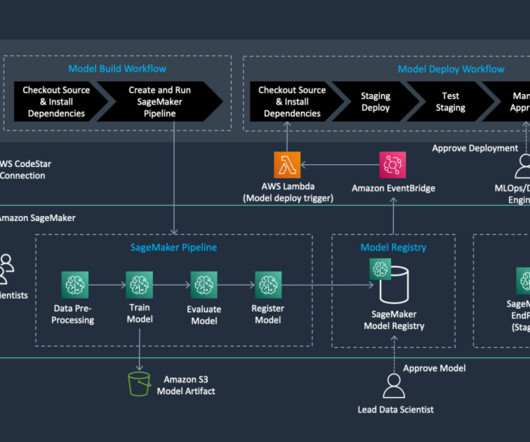
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. You can create event-driven workflows triggered by specific events, like when code is pushed to a repository or a pull request is created.
25 Enterprise LLM Summit: Building GenAI with Your Data drew over a thousand engaged attendees across three and a half hours and nine sessions. The eight speakers at the event—the second in our Enterprise LLM series—united around one theme: AI data development drives enterprise AI success. Snorkel AI’s Jan.
It offers its users advanced machine learning, data management , and generative AI capabilities to train, validate, tune and deploy AI systems across the business with speed, trusted data, and governance. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
DataRobot now delivers both visual and code-centric datapreparation and data pipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Virtual Event. Finally, I’m excited to announce nearly 100 new features in DataRobot 7.2 September 23.
This enables employees to see data details like definitions and formulas, lineage and ownership information, as well as important data quality notifications, from certification status to events, like if a data source refresh failed and the information isn’t up to date. Data modeling. Data migration .
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content