This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today’s question is, “What does a datascientist do.” ” Step into the realm of data science, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of datascientists.
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production.
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
It also enables you to evaluate the models using advanced metrics as if you were a datascientist. We explain the metrics and show techniques to deal with data to obtain better model performance. Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building.
It combines elements of statistics, mathematics, computer science, and domain expertise to extract meaningful patterns from large volumes of data. Role of DataScientists in Modern Industries DataScientists drive innovation and competitiveness across industries in today’s fast-paced digital world.
From datapreparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications. Unified ML Workflow: Vertex AI provides a simplified ML workflow, encompassing data ingestion, analysis, transformation, model training, evaluation, and deployment.
With sports (and everything else) cancelled, this datascientist decided to take on COVID-19 | A Winner’s Interview with David Mezzetti When his hobbies went on hiatus, Kaggler David Mezzetti made fighting COVID-19 his mission. The early days of the effort were spent on EDA and exchanging ideas with other members of the community.
It simplifies the creation of complex visualisations, making it a go-to tool for DataScientists and analysts. Seaborn integrates seamlessly with Pandas data structures, allowing users to create plots directly from DataFrame objects. Aesthetic Mapping: Utilises color, size, and shape to represent data variables.
Note : Now, Start joining Data Science communities on social media platforms. These communities will help you to be updated in the field, because there are some experienced datascientists posting the stuff, or you can talk with them so they will also guide you in your journey.
DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes. This section explores the essential steps in preparingdata for AI applications, emphasising data quality’s active role in achieving successful AI models.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Exploratory data analysis (EDA) and modeling.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
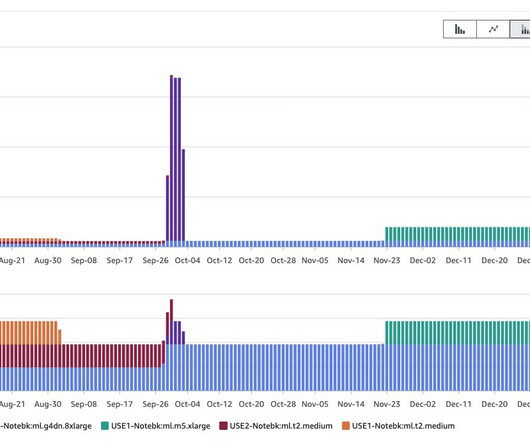
For ML model development, the size of a SageMaker notebook instance depends on the amount of data you need to load in-memory for meaningful exploratory data analyses (EDA) and the amount of computation required. As with SageMaker notebooks, you can also feed AWS CUR data into QuickSight for reporting or visualization purposes.
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. Versioning of dataset During the development of an algorithm, a DataScientist might have to run multiple experiments. via Data Connectors.
The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers. For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023.
Email classification project diagram The workflow consists of the following components: Model experimentation – Datascientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratory data analysis (EDA), data cleaning and preparation, and building prototype models.
The points to cover in this article are as follows: Generating synthetic data to illustrate ML modelling for election outcomes. Providing some insights into how datascientists might approach real-life election predictions. Model Fitting and Training: Various ML models trained on sub-patterns in data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content