This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. You can download the dataset loans-part-1.csv
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. Imagine a database with billions of samples ( ) (e.g., So, how can we perform efficient searches in such big databases?
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. script to download the model and tokenizer. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Image Retrieval with IBM watsonx.data and Milvus (Vector) Database : A Deep Dive into Similarity Search What is Milvus? Milvus is an open-source vector database specifically designed for efficient similarity search across large datasets. DataPreparation Here we use a subset of the ImageNet dataset (100 classes).
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, preparedata for analytics and ML, and train ML models. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. option("multiLine", "true").option("header",
Whats AI Weekly Whether youre building recommendation systems like Netflix, Spotify, or any AI-driven application, vector databases provide the performance, scalability, and flexibility needed to handle large, complex datasets. Download it here and support a fellow community member. AI poll of the week!
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Download the Machine Learning Project Checklist. Download Now. Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Predictions can be saved to a database or used immediately in another process. Exploring and Transforming Data.
If the gloss is not available in the GenASL database, the logic falls back to fingerspelling each alphabet letter. You can download and install Docker from Docker’s official website. This instance will be used for various tasks such as video processing and datapreparation. AWS SAM CLI – Install the AWS SAM CLI.
Meta Llama3 8B is a gated model on Hugging Face, which means that users must be granted access before they’re allowed to download and customize the model. QLoRA quantizes a pretrained language model to 4 bits and attaches smaller low-rank adapters (LoRA), which are fine-tuned with our training data.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. For Prepare template , select Template is ready. Enter a stack name, such as Demo-Redshift.
You can watch the full video of this session here and download the slideshere. Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. For instance: DataPreparation: GoogleSheets.
Jump Right To The Downloads Section What Is Locality Sensitive Hashing (LSH)? SimHash: LSH for Vector Databases SimHash is a specific type of Locality Sensitive Hashing (LSH) designed to efficiently detect near-duplicate documents and perform similarity searches in large-scale vector databases.
Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform datapreparation and transformation, build ML models, and deploy these models into a governed workflow. Download the following student dataset to your local computer. Set up SageMaker Canvas. csv dataset into SageMaker Canvas.
Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. The following screenshot shows the Data Catalog schema. Access permission to the AWS Glue databases and tables are managed by AWS Lake Formation.
Challenges associated with these stages involve not knowing all touchpoints where data is persisted, maintaining a data pre-processing pipeline for document chunking, choosing a chunking strategy, vector database, and indexing strategy, generating embeddings, and any manual steps to purge data from vector stores and keep it in sync with source data.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
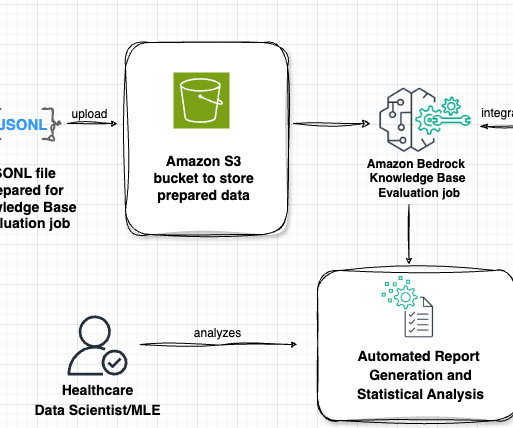
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
Alteryx provides organizations with an opportunity to automate access to data, analytics , data science, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and data science.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Dolt Dolt is an open-source relational database system built on Git.
Open-source models are (in general) always fine-tunable because the model artifacts are available for downloading and the users are able to extend and use them at will. Additions are required in historical datapreparation, model evaluation, and monitoring. Proprietary models might sometimes offer the option of fine-tuning.
Users can download datasets in formats like CSV and ARFF. How to Access and Use Datasets from the UCI Repository The UCI Machine Learning Repository offers easy access to hundreds of datasets, making it an invaluable resource for data scientists, Machine Learning practitioners, and researchers. CSV, ARFF) to begin the download.
Solution overview In this solution, we start with datapreparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors.
The publicly available Llama models have been downloaded more than 30M times, and customers love that Amazon Bedrock offers them as part of a managed service where they don’t need to worry about infrastructure or have deep ML expertise on their teams. or “Should I use a relational or non-relational database?”).
It is designed to enhance the performance of generative models by providing them with highly relevant context retrieved from a large database or knowledge base. Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. ✓ Access on mobile, laptop, desktop, etc.
Pixlr Pixlr s AI-powered online editor offers advanced image manipulation without requiring software downloads. These AI-powered platforms enhance decision-making, automate reporting, and simplify complex data operations. Its great for social media graphics, ads, and quick visual touch-ups.
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial datapreparation routine and generate accurate predictions without writing code.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content