This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether you’re an expert, a curious learner, or just love data science and AI, there’s something here for you to learn about the fundamental concepts. They cover everything from the basics like embeddings and vector databases to the newest breakthroughs in tools. Link to blog -> What is LangChain?
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Database name : Enter dev. Choose Add connection.
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. What is Retrieval-Augmented Generation (RAG) and when to use it Retrieval-Augmented Generation (RAG) is a method that integrates the capabilities of a language model with a specific library or database.
Datapreparation is a crucial step in any machinelearning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
These skills include programming languages such as Python and R, statistics and probability, machinelearning, data visualization, and data modeling. This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data.
Dataiku is an advanced analytics and machinelearning platform designed to democratize data science and foster collaboration across technical and non-technical teams. Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machinelearning models.
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. For instructions to catalog the data, refer to Populating the AWS Glue Data Catalog.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
Data mining is a fascinating field that blends statistical techniques, machinelearning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. However, instead of using Hadoop, data lakes are increasingly being constructed using cloud object storage services.
Data is at the heart of machinelearning (ML). Including relevant data to comprehensively represent your business problem ensures that you effectively capture trends and relationships so that you can derive the insights needed to drive business decisions. Expand the Data Source menu and choose Athena. Choose Next.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Universities and other higher learning institutions have collected massive amounts of data over the years, and now they are exploring options to use that data for deeper insights and better educational outcomes. You can use machinelearning (ML) to generate these insights and build predictive models.
A study published in the Journal of MachineLearning Research indicates that RAG can improve response accuracy by over 30% compared to traditional methods. Each vector represents specific features or characteristics of the data, allowing for efficient storage and retrieval.
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. Imagine a database with billions of samples ( ) (e.g., So, how can we perform efficient searches in such big databases?
With organizations increasingly investing in machinelearning (ML), ML adoption has become an integral part of business transformation strategies. The accelerator also includes connections with Amazon DataZone for sharing, searching, and discovering data at scale across organizational boundaries to generate and enrich models.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. RPA tools can be programmed to interact with various systems, such as web applications, databases, and desktop applications. What is machinelearning (ML)?
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Specifically, we clean the data and create RAG artifacts to answer the questions about the content of the dataset. Access to Amazon OpenSearch as a vector database. This will land on a data flow page.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job. Datapreparation The foundation of successful language model fine tuning lies in properly structured and prepared training data.
Image Retrieval with IBM watsonx.data and Milvus (Vector) Database : A Deep Dive into Similarity Search What is Milvus? Milvus is an open-source vector database specifically designed for efficient similarity search across large datasets. DataPreparation Here we use a subset of the ImageNet dataset (100 classes).
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components: Indexing : Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database. Python script that serves as the entry point.
Summary: The UCI MachineLearning Repository, established in 1987, is a crucial resource for MachineLearning practitioners. It supports various learning tasks, including classification and regression, and is organised by type and domain, facilitating easy access for users worldwide.
Machinelearning (ML) is only possible because of all the data we collect. However, with data coming from so many different sources, it doesn’t always come in a format that’s easy for ML models to understand. Why PrepareData for MachineLearning Models?
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion by 2031, growing at a CAGR of 34.20%.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors.
For readers who work in ML/AI, it’s well understood that machinelearning models prefer feature vectors of numerical information. However, the majority of enterprise data remains unleveraged from an analytics and machinelearning perspective, and much of the most valuable information remains in relational database schemas such as OLAP.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machinelearning (ML) workflows without writing any code.
At a basic level, MachineLearning (ML) technology learns from data to make predictions. Businesses use their data with an ML-powered personalization service to elevate their customer experience. This approach allows businesses to use data to derive actionable insights and help grow their revenue and brand loyalty.
They are typically created by training a machinelearning model on a large corpus of text. The model learns to associate each word with a vector of numbers. The resulting vector representations can then be stored in a vector database. This could involve using a hierarchical file system or a database.
With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data. You only need to provide a relevant data file as input and choose your FM to get started.
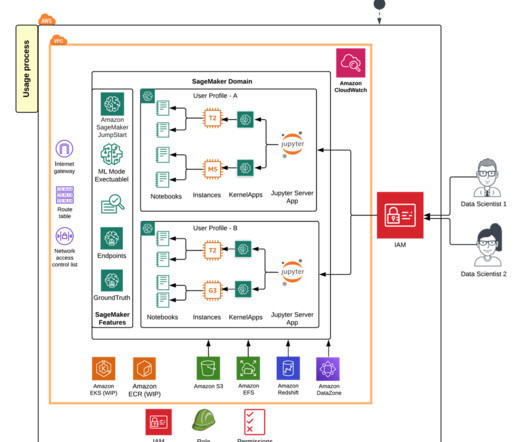
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
However, building advanced data-driven applications poses several challenges. First, it can be time consuming for users to learn multiple services development experiences. Third, configuring and governing access to appropriate users for data, code, development artifacts, and compute resources across services is a manual process.
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Writing Output: Centralizing data into a structure, like a delta table.
How to Use MachineLearning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machinelearning were introduced.
Now all you need is some guidance on generative AI and machinelearning (ML) sessions to attend at this twelfth edition of re:Invent. Embeddings can be stored in a database and are used to enable streamlined and more accurate searches. Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas!
In programming, You need to learn two types of language. One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. There is one Query language known as SQL (Structured Query Language), which works for a type of database. Why do we need databases?
With data visualization capabilities, advanced statistical analysis methods and modeling techniques, IBM SPSS Statistics enables users to pursue a comprehensive analytical journey from datapreparation and management to analysis and reporting.
SageMaker Studio is a single web-based interface for end-to-end machinelearning (ML) development. QLoRA quantizes a pretrained language model to 4 bits and attaches smaller low-rank adapters (LoRA), which are fine-tuned with our training data. Your job is to answer questions about a database.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machinelearning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content