This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Database name : Enter dev. Choose Add connection.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
With data software pushing the boundaries of what’s possible in order to answer business questions and alleviate operational bottlenecks, data-driven companies are curious how they can go “beyond the dashboard” to find the answers they are looking for. One of the standout features of Dataiku is its focus on collaboration.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
In this post, we highlight the advanced data augmentation techniques and performance improvements in Amazon Bedrock Model Distillation with Metas Llama model family. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Specifically, we clean the data and create RAG artifacts to answer the questions about the content of the dataset. Access to Amazon OpenSearch as a vector database. This will land on a data flow page.
The following screenshot shows the Data Catalog schema. Access permission to the AWS Glue databases and tables are managed by AWS Lake Formation. You can find the AWS Glue database name on the Outputs tab of the CloudFormation stack. We have completed the datapreparation step. Choose Create data source.
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components: Indexing : Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database. writefile opt/ml/model/inference.py
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. ML models don’t operate in isolation. This necessitates considering the entire ML lifecycle during design and development.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Data scientist experience In this section, we cover how data scientists can connect to Snowflake as a data source in Data Wrangler and preparedata for ML.
At a basic level, Machine Learning (ML) technology learns from data to make predictions. Businesses use their data with an ML-powered personalization service to elevate their customer experience. This approach allows businesses to use data to derive actionable insights and help grow their revenue and brand loyalty.
You can use machine learning (ML) to generate these insights and build predictive models. Educators can also use ML to identify challenges in learning outcomes, increase success and retention among students, and broaden the reach and impact of online learning content. Import the Dropout_Academic Success - Sheet1.csv
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
For readers who work in ML/AI, it’s well understood that machine learning models prefer feature vectors of numerical information. However, the majority of enterprise data remains unleveraged from an analytics and machine learning perspective, and much of the most valuable information remains in relational database schemas such as OLAP.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and preparedata for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. This allows for data to be aggregated for further manufacturer-agnostic analysis.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data. You only need to provide a relevant data file as input and choose your FM to get started.
By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, ML engineers, and application developers to harness the full potential of FMs while addressing unique application requirements. SageMaker Studio is a single web-based interface for end-to-end machine learning (ML) development.
Data is at the heart of machine learning (ML). Including relevant data to comprehensively represent your business problem ensures that you effectively capture trends and relationships so that you can derive the insights needed to drive business decisions. This dataset then needs to be imported into a separate application for ML.
To address potential fairness concerns, it can be helpful to evaluate disparities and imbalances in training data or outcomes. Amazon SageMaker Clarify helps identify potential biases during datapreparation without requiring code. Davide Gallitelli is a Senior Specialist Solutions Architect for AI/ML in the EMEA region.
With organizations increasingly investing in machine learning (ML), ML adoption has become an integral part of business transformation strategies. However, implementing ML into production comes with various considerations, notably being able to navigate the world of AI safely, strategically, and responsibly.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring.
Only involving necessary people to do case validation or augmentation tasks reduces the risk of document mishandling and human error when dealing with sensitive data. Sensitive data in these data stores needs to be secured. You can either secure the output PII in your data store or redact the PII in your IDP output.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
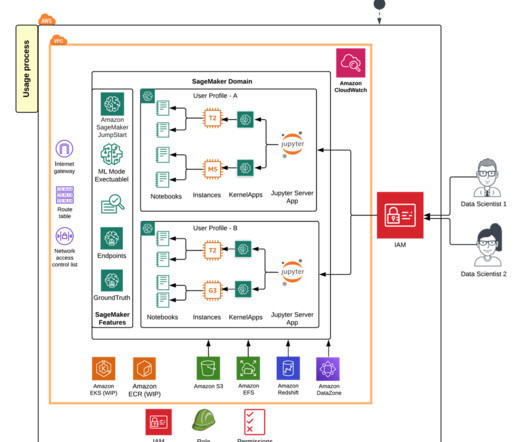
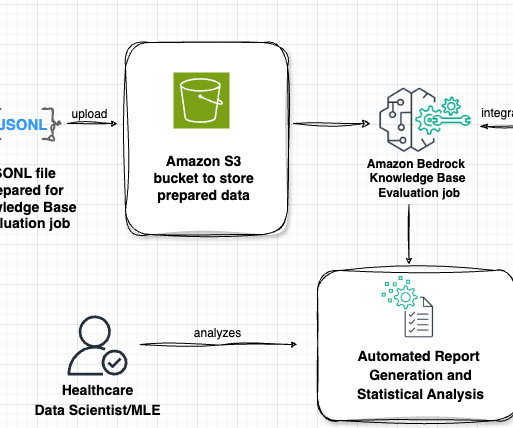
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. Some of the models offer capabilities for you to fine-tune them with your own data.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
aws sagemaker create-cluster --cli-input-json file://cluster-config.json --region $AWS_REGION You should be able to see your cluster by navigating to SageMaker Hyperpod in the AWS Management Console and see a cluster named ml-cluster listed. After a few minutes, its status should change from Creating to InService.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content