This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unsupervised models Unsupervised models typically use traditional statistical methods such as logistic regression, time series analysis, and decisiontrees. These methods analyze data without pre-labeled outcomes, focusing on discovering patterns and relationships.
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. The data mining process The data mining process is structured into four primary stages: data gathering, datapreparation, data mining, and data analysis and interpretation.
Deep learning algorithms Deep learning techniques are among the most effective for creating synthetic data, leveraging neural networks to learn complex patterns from real datasets and generate new, similar datasets. Organizations can take advantage of numerous open-source tools available for data synthesis.
In the world of Machine Learning and Data Analysis , decisiontrees have emerged as powerful tools for making complex decisions and predictions. These tree-like structures break down a problem into smaller, manageable parts, enabling us to make informed choices based on data. What is a DecisionTree?
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. What is DecisionTree in Machine Learning?
Normalization A feature scaling technique is often applied as part of datapreparation for machine learning. The goal of normalization is to change the value of numeric columns in the dataset to use a common scale, without distorting differences in the range of values or losing any information.
Machine learning algorithms Machine learning forms the core of Applied Data Science. It leverages algorithms to parse data, learn from it, and make predictions or decisions without being explicitly programmed.
Data Sourcing. Fundamental to any aspect of data science, it’s difficult to develop accurate predictions or craft a decisiontree if you’re garnering insights from inadequate data sources.
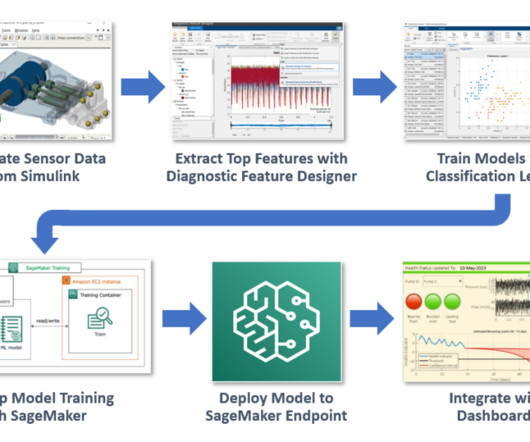
First, we extract features from a subset of the full dataset using the Diagnostic Feature Designer app, and then run the model training locally with a MATLAB decisiontree model. Part 1: Datapreparation & feature extraction The first step in any machine learning project is to prepare your data.
2nd Place: Yuichiro “Firepig” [Japan] Firepig created a three-step model that used decisiontrees, linear regression, and random forests to predict tire strategies, laps per stint, and average lap times. Yunus secured third place by delivering a flexible, well-documented solution that bridged data science and Formula 1 strategy.
DataPreparation for Demand Forecasting High-quality data is the cornerstone of effective demand forecasting. Just like building a house requires a strong foundation, building a reliable forecast requires clean and well-organized data. They are particularly effective when dealing with high-dimensional data.
The platform employs an intuitive visual language, Alteryx Designer, streamlining datapreparation and analysis. With Alteryx Designer, users can effortlessly input, manipulate, and output data without delving into intricate coding, or with minimal code at most. What is Alteryx Designer?
DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes. This section explores the essential steps in preparingdata for AI applications, emphasising data quality’s active role in achieving successful AI models.
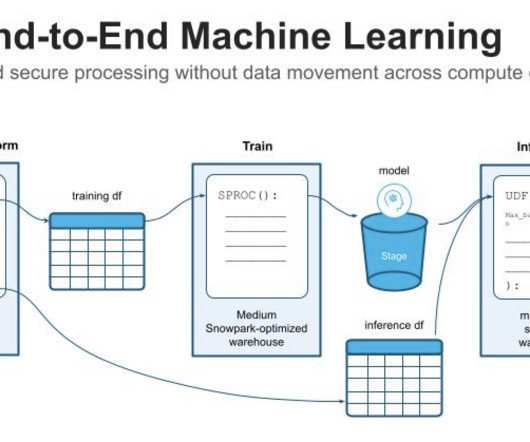
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., On Lines 21-27 , we define a Node class, which represents a node in a decisiontree.
They identify patterns in existing data and use them to predict unknown events. Techniques like linear regression, time series analysis, and decisiontrees are examples of predictive models. Start by collecting data relevant to your problem, ensuring it’s diverse and representative.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: Data Ingestion: Collecting data from various sources and ensuring it’s available for analysis. DataPreparation: Cleaning and transforming raw data to make it usable for machine learning.
Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering. Datapreparation To extract data efficiently for training and testing, we utilize Amazon Athena and the AWS Glue Data Catalog.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks.
Introduction Boosting is a powerful Machine Learning ensemble technique that combines multiple weak learners, typically decisiontrees, to form a strong predictive model. It identifies the optimal path for missing data during tree construction, ensuring the algorithm remains efficient and accurate. Lower values (e.g.,
The quality and quantity of data collected play a crucial role in the accuracy of predictions. DataPreparation Once the data is collected, it must be cleaned and prepared for analysis. This involves removing duplicates, correcting errors, and formatting the data appropriately.
With a modeled estimation of the applicant’s credit risk, lenders can make more informed decisions and reduce the occurrence of bad loans, thereby protecting their bottom line. More recently, ensemble methods and deep learning models are being explored for their ability to handle high-dimensional data and capture complex patterns.
DecisionTrees ML-based decisiontrees are used to classify items (products) in the database. This is the applied machine learning algorithm that works with tabular and structured data. In its core, lie gradient-boosted decisiontrees. Data visualization charts and plot graphs can be used for this.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
This involves: DataPreparation : Collect and preprocess data to ensure it is suitable for training your model. neural networks, decisiontrees) based on your application’s requirements. Develop AI Algorithms in MATLAB In this step, you will develop and train your AI algorithms using MATLAB.
Augmented Analytics Combining Artificial Intelligence with traditional analytics allows businesses to gain insights more quickly by automating datapreparation processes. Machine Learning Expertise Familiarity with a range of Machine Learning algorithms is crucial for Data Science practitioners.
It’s critical in harnessing data insights for decision-making, empowering businesses with accurate forecasts and actionable intelligence. Choosing Appropriate Algorithms Choosing the correct algorithm depends on the problem and data. Verify that the data is accurate, complete, and up-to-date.
Augmented Analytics Augmented analytics is revolutionising the way businesses analyse data by integrating Artificial Intelligence (AI) and Machine Learning (ML) into analytics processes. Dive Deep into Machine Learning and AI Technologies Study core Machine Learning concepts, including algorithms like linear regression and decisiontrees.
Lesson 1: Mitigating data sparsity problems within ML classification algorithms What are the most popular algorithms used to solve a multi-class classification problem? As this method works on distance metrics, the success of these networks depends on these networks’ understanding of similarity relationships among samples.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. Data Transformation Transforming dataprepares it for Machine Learning models. It’s simple but effective for many problems like predicting house prices.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Check out the previous post to get a primer on the terms used) Outline Dealing with Class Imbalance Choosing a Machine Learning model Measures of Performance DataPreparation Stratified k-fold Cross-Validation Model Building Consolidating Results 1. DataPreparation Photo by Bonnie Kittle […]
CatBoost is quickly becoming a go-to algorithm in the machine learning landscape, particularly for its innovative approach to handling categorical data. Developed by Yandex, it leverages gradient-boosting decisiontrees, making it easier to build and train robust models without the complexity typically associated with data preprocessing.
Decisiontrees: They segment data into branches based on sequential questioning. Unsupervised algorithms In contrast, unsupervised algorithms analyze data without pre-existing labels, identifying inherent structures and patterns. Random forest: Combines multiple decisiontrees to strengthen predictive capabilities.
It groups similar data points or identifies outliers without prior guidance. Type of Data Used in Each Approach Supervised learning depends on data that has been organized and labeled. This datapreparation process ensures that every example in the dataset has an input and a known output.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content