This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This lesson is the 1st in a 2-part series on Mastering Approximate Nearest Neighbor Search : Implementing Approximate Nearest Neighbor Search with KD-Trees (this tutorial) Approximate Nearest Neighbor with Locality Sensitive Hashing (LSH) To learn how to implement an approximate nearest neighbor search using KD-Tree , just keep reading.
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Instead, we use pre-trained deeplearning models like VGG or ResNet to extract feature vectors from the images. Image retrieval search architecture The architecture follows a typical machine learning workflow for image retrieval. DataPreparation Here we use a subset of the ImageNet dataset (100 classes).
In such situations, it may be desirable to have the data accessible to SageMaker in the ephemeral storage media attached to the ephemeral training instances without the intermediate storage of data in Amazon S3. We add this data to Snowflake as a new table. Launch a SageMaker Training job for training the ML model.
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., To download our dataset and set up our environment, we will install the following packages.
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. The Docker images are preinstalled and tested with the latest versions of popular deeplearning frameworks as well as other dependencies needed for training and inference.
Customers increasingly want to use deeplearning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII). Download the SageMaker Data Wrangler flow.
Open NN OpenNN stands out as a powerful software library specifically designed for the implementation of neural networks, a central aspect of machine learning. As an open-source library coded in C++, OpenNN offers the ability to handle complex machine learning tasks with optimal performance.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
The Step Functions workflow has three steps: Convert the audio input to English text using Amazon Transcribe, an automatic speech-to-text AI service that uses deeplearning for speech recognition. You can download and install Docker from Docker’s official website. AWS SAM CLI – Install the AWS SAM CLI.
SageMaker notably supports popular deeplearning frameworks, including PyTorch, which is integral to the solutions provided here. Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics.
In this story, we talk about how to build a DeepLearning Object Detector from scratch using TensorFlow. Most of machine learning projects fit the picture above Once you define these things, the training is a cat-and-mouse game where you need “only” tuning the training hyperparameters in order to achieve the desired performance.
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Anomaly detection ( Figure 2 ) is a critical technique in data analysis used to identify data points, events, or observations that deviate significantly from the norm.
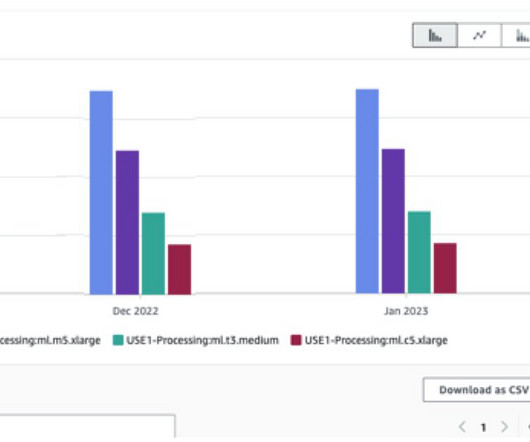
Data preprocessing holds a pivotal role in a data-centric AI approach. However, preparing raw data for ML training and evaluation is often a tedious and demanding task in terms of compute resources, time, and human effort. As mentioned earlier, SageMaker Processing also supports Athena and Amazon Redshift as data sources.
This lesson is the last in a 2-part series on Mastering Approximate Nearest Neighbor Search : Implementing Approximate Nearest Neighbor Search with KD-Trees Approximate Nearest Neighbor with Locality Sensitive Hashing (LSH) (this tutorial) To learn how to implement LSH for approximate nearest neighbor search, just keep reading. Thakur, eds.,
A guide to train YoloV7 model on custom dataset using Python Source:Author Introduction DeepLearning (DL) technologies are now being widely adopted by different organizations that want to improve their services in no time along with great accuracy. Object detection is one of the most important concepts in the deeplearning space.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
For Prepare template , select Template is ready. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. After you finish datapreparation, you can use SageMaker Data Wrangler to export features to SageMaker Feature Store.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML. Choose Create.
Open-source models are (in general) always fine-tunable because the model artifacts are available for downloading and the users are able to extend and use them at will. The journey of providers FM providers need to train FMs, such as deeplearning models. Proprietary models might sometimes offer the option of fine-tuning.
DataPreparation You will use the Ants and Bees classification dataset available on Kaggle. To download it, you will use the Kaggle package. Create your API keys on your Account’s Settings page and it will download a JSON file. Open it, copy the username and key, and set the environment variables as shown below.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Monitor the performance of machine learning models.
Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. For more information, refer to Granting Data Catalog permissions using the named resource method. We have completed the datapreparation step.
Recent years have shown amazing growth in deeplearning neural networks (DNNs). In Steps 1–5, we download and prepare the data, create the xgb3 estimator (the distributed XGBoost estimator is set to use three instances), run the training jobs, and observe the results. International Conference on Machine Learning.
Jump Right To The Downloads Section Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series Introduction Image segmentation is a pivotal task in computer vision where each pixel in an image is assigned a specific label, effectively dividing the image into distinct regions. Looking for the source code to this post?
Credits A critical component for these robots is to identify different objects and take actions accordingly and this is where DeepLearning and Machine Vision enters the space!!! DataPreparation The Training dataset is labeled as per Pascal VOC format (XML files) PASCAL-VOC Format. Cuda — 9.0, Runs on colab too!!!
TensorFlow and Keras have emerged as powerful frameworks for building and training deeplearning models. Whether you are an experienced machine learning practitioner or just starting your journey in deeplearning, this article will provide practical strategies and tips to leverage Comet effectively.
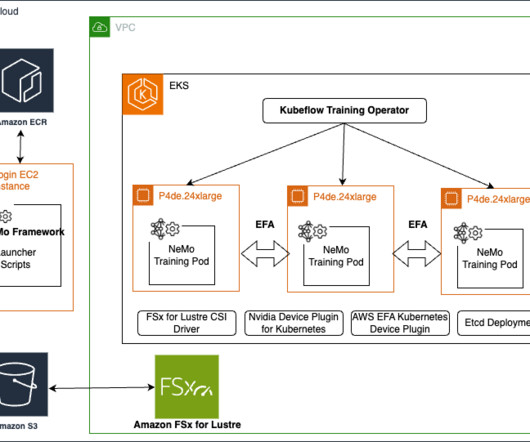
The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment. To get around this, you can put the launcher scripts in the head node and the results and data folder in the file system that the compute nodes have access to.
Databricks is getting up to 40% better price-performance with Trainium-based instances to train large-scale deeplearning models. Customers like Ricoh have trained a Japanese LLM with billions of parameters in mere days. Llama 2 70B is suitable for large-scale tasks such as language modeling, text generation, and dialogue systems.
At its core, NeMo Framework provides model builders with: Comprehensive development tools : A complete ecosystem of tools, scripts, and proven recipes that guide users through every phase of the LLM lifecycle, from initial datapreparation to final deployment. SageMaker HyperPod uses lifecycle scripts to bootstrap a cluster.
Jump Right To The Downloads Section Understanding Network Intrusion and the Role of Anomaly Detection Imagine a scenario where a large financial institution suddenly notices an unusual spike in network traffic late at night. We will start by setting up libraries and datapreparation. Looking for the source code to this post?
Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. Data Curation in LLaVA Datapreparation in LLaVA is a three-tiered process: Conversational Data: Curating dialogues for interaction-focused tasks. Or requires a degree in computer science?
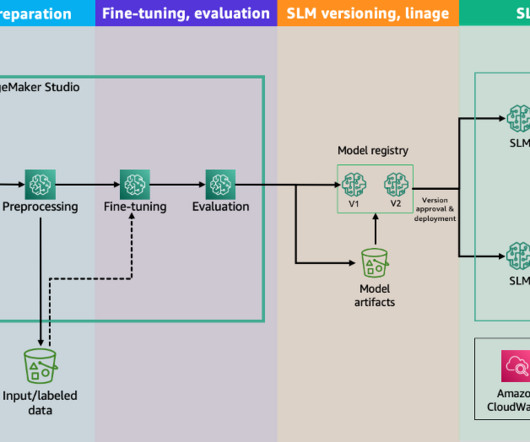
Solution overview This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps: Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required datapreparation steps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content