This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Regardless of your industry, whether it’s an enterprise insurance company, pharmaceuticals organization, or financial services provider, it could benefit you to gather your own data to predict future events. DeepLearning, Machine Learning, and Automation.
A complete guide to building a deeplearning project with PyTorch, tracking an Experiment with Comet ML, and deploying an app with Gradio on HuggingFace Image by Freepik AI tools such as ChatGPT, DALL-E, and Midjourney are increasingly becoming a part of our daily lives. These tools were developed with deeplearning techniques.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
First, we have data scientists who are in charge of creating and training machine learning models. They might also help with datapreparation and cleaning. The machine learning engineers are in charge of taking the models developed by data scientists and deploying them into production.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation.
A DataBrew job extracts the data from the TR data warehouse for the users who are eligible to provide recommendations during renewal based on the current subscription plan and recent activity. The real-time integration starts with collecting the live user engagement data and streaming it to Amazon Personalize.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
Customers increasingly want to use deeplearning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII).
Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.” Let’s be honest — one-hot-encoding isn’t the most thrilling or challenging task on a data scientist’s to-do list. One might say that tabular data modeling is the original data-centric AI!
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
The Step Functions workflow has three steps: Convert the audio input to English text using Amazon Transcribe, an automatic speech-to-text AI service that uses deeplearning for speech recognition. This instance will be used for various tasks such as video processing and datapreparation.
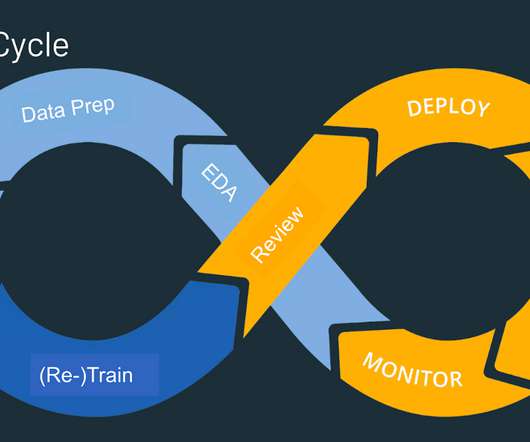
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Monitor the performance of machine learning models.
It leverages sentence transformers to embed the text data and fine-tunes the head layer to perform the classification task. SetFit's two-stage training process — src Few-Shot Training — DataPreparation As explained, we are all set to train the SetFit model with a handful of data.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML. Choose Create.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. And although generative AI has appeared in previous events, this year we’re taking it to the next level. Also, hear how Flip AI built their own models using these AWS services. Reserve your seat now!
Thirdly, the presence of GPUs enabled the labeled data to be processed. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed.
Machine Learning Frameworks Comet integrates with a wide range of machine learning frameworks, making it easy for teams to track and optimize their models regardless of the framework they use. Ludwig Ludwig is a machine learning framework for building and training deeplearning models without the need for writing code.
See also MLOps Problems and Best Practices Addressing model environments Use ONNX ONNX ( Open Neural Network Exchange) | Source ONNX (Open Neural Network Exchange), an open-source format for representing deeplearning models, was developed by Microsoft and is now managed by the Linux Foundation.
Anomaly detection ( Figure 2 ) is a critical technique in data analysis used to identify data points, events, or observations that deviate significantly from the norm. We will start by setting up libraries and datapreparation. fraud, network intrusions, or system failures). for 3000+ credit card transactions.
Using PyTorch DeepLearning Framework and CNN Architecture Photo by Andrew S on Unsplash Motivation Build a proof-of-concept for Audio Classification using a deep-learning neural network with PyTorch framework. Data Source here. This is inherently a supervised learning problem.
DataPreparation for Demand Forecasting High-quality data is the cornerstone of effective demand forecasting. Just like building a house requires a strong foundation, building a reliable forecast requires clean and well-organized data. Ensemble Learning Combine multiple forecasting models (e.g.,
A guide to train YoloV7 model on custom dataset using Python Source:Author Introduction DeepLearning (DL) technologies are now being widely adopted by different organizations that want to improve their services in no time along with great accuracy. Object detection is one of the most important concepts in the deeplearning space.
DataPreparation You will use the Ants and Bees classification dataset available on Kaggle. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners.
Steps indicating how to use ELECTRA for sentiment analysis are listed below: DataPreparation: The first step is to collect and prepare a labeled dataset for training the sentiment analysis model. With the development of the ELECTRA pre-training technique, sentiment analysis can be performed more accurately and efficiently.
SageMaker JumpStart SageMaker JumpStart serves as a model hub encapsulating a broad array of deeplearning models for text, vision, audio, and embedding use cases. Often, to get an NLP application working for production use cases, we end up having to think about datapreparation and cleaning.
Improve the quality and time to market for deeplearning models in diagnostic medical imaging. Access to AWS environments SageMaker and associated AI/ML services are accessed with security guardrails for datapreparation, model development, training, annotation, and deployment.
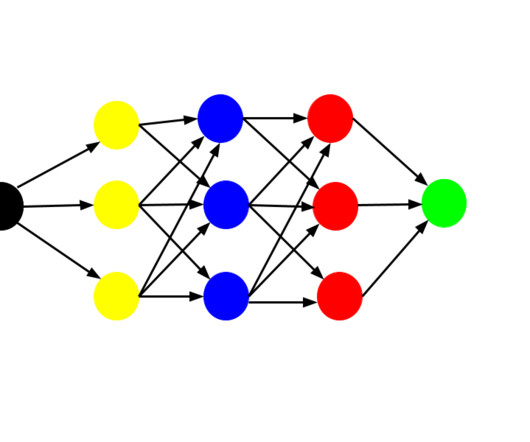
AlexNet significantly improved performance over previous approaches and helped popularize deeplearning and CNNs. This helps avoid disappearing gradients in very deep networks, allowing ResNet to attain cutting-edge performance on a wide range of computer vision applications.
TensorFlow and Keras have emerged as powerful frameworks for building and training deeplearning models. Whether you are an experienced machine learning practitioner or just starting your journey in deeplearning, this article will provide practical strategies and tips to leverage Comet effectively.
Here’s a closer look at their core responsibilities and daily tasks: Designing and Implementing Models: Developing and deploying Machine Learning models using Azure Machine Learning and other Azure services. DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling.
It identifies the optimal path for missing data during tree construction, ensuring the algorithm remains efficient and accurate. This feature eliminates the need for preprocessing steps like imputation, saving time in datapreparation. This ensures better predictions for rare events.
MLOps, on the other hand, is a broader framework for managing the lifespan of machine learning models. Typically, MLOps systems include capabilities for automating the whole ML lifecycle, from datapreparation through model training and deployment. If you'd like to contribute, head on over to our call for contributors.
Data preprocessing holds a pivotal role in a data-centric AI approach. However, preparing raw data for ML training and evaluation is often a tedious and demanding task in terms of compute resources, time, and human effort. For more information, see Amazon EventBridge pricing.
Using skills such as statistical analysis and data visualization techniques, prompt engineers can assess the effectiveness of different prompts and understand patterns in the responses. You can also get data science training on-demand wherever you are with our Ai+ Training platform. Interested in attending an ODSC event?
LLM models are large deeplearning models that are trained on vast datasets, are adaptable to various tasks and specialize in NLP tasks. They are characterized by their enormous size, complexity, and the vast amount of data they process. LLMOps focuses specifically on the operational aspects of large language models (LLMs).
Sorting Algorithms Sorting algorithms play a crucial role in datapreparation. Algorithms with low complexity for processing training data are crucial for faster model development and iteration cycles. Data Cleaning and Preprocessing Cleaning and preparing messy real-world data can be computationally expensive.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deeplearning algorithms to forecast sales, predict customer churn and fraud detection, etc., Most of its products use machine learning or deeplearning models for some or all of their features.
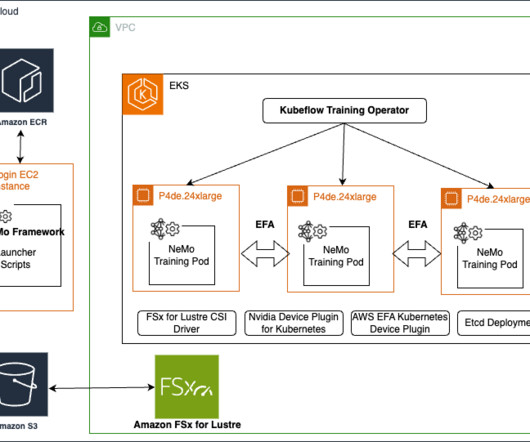
The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment. To get around this, you can put the launcher scripts in the head node and the results and data folder in the file system that the compute nodes have access to.
The Github merge event triggers our Jenkins CI pipeline, which in turn starts a SageMaker Pipelines job with test data. Model deployment – After making sure that everything is running as expected, data scientists merge the develop branch into the primary branch. A test endpoint is deployed for testing purposes. Use Version 2.x
Databricks is getting up to 40% better price-performance with Trainium-based instances to train large-scale deeplearning models. This means they need a real choice of model providers (which the events of the past 10 days have made even more clear). Customers need to be trying out different models.
While every events lineup is unique and changes based on industry trends and needs, we reinvite many speakers each time as the attendees have made it clear that these AI professionals are cant-miss speakers, and they always get positive feedback.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content