This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. and above. amazonaws.com/djl-inference:0.29.0-tensorrtllm0.11.0-cu124",
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
As machine learning (ML) becomes increasingly prevalent in a wide range of industries, organizations are finding the need to train and serve large numbers of ML models to meet the diverse needs of their customers. Here, the checkpoints need to be saved in a pre-specified location, with the default being /opt/ml/checkpoints.
Model tuning is the experimental process of finding the optimal parameters and configurations for a machine learning (ML) model that result in the best possible desired outcome with a validation dataset. Single objective optimization with a performance metric is the most common approach for tuning ML models.
Pietro Jeng on Unsplash MLOps is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. Thus, MLOps is the intersection of Machine Learning, DevOps, and Data Engineering (Figure 1). There is no central store to manage models (versions and stage transitions).
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. No definite pneumonia.
In fact, AI/ML graduate textbooks do not provide a clear and consistent description of the AI software engineering process. Therefore, I thought it would be helpful to give a complete description of the AI engineering process or AI Process, which is described in most AI/ML textbooks [5][6]. 85% or more of AI projects fail [1][2].
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
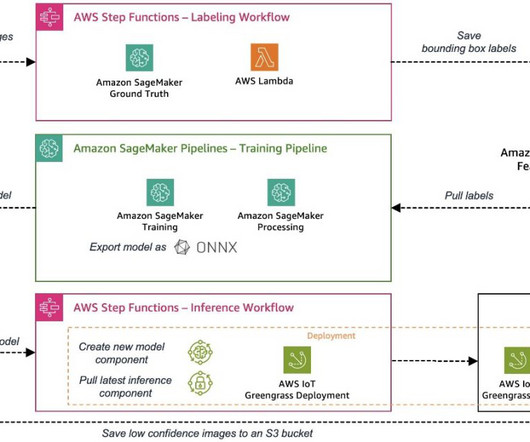
Solution overview In Part 1 of this series, we laid out an architecture for our end-to-end MLOps pipeline that automates the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. In Part 2 , we showed how to automate the labeling and model training parts of the pipeline.
ML enters the picture … Image Source² Recent advances show promise for neural program analyses around complex concepts such as program invariants, inter-procedural properties, and even evidence of deeper semantic meaning. Therefore, it is logical to question whether an ML system can effectively answer such semantic queries.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machine learning were introduced.
The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. compute.internal.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. py"): estimator_name = script.split(".")[0].replace("_",
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
AWS innovates to offer the most advanced infrastructure for ML. For ML specifically, we started with AWS Inferentia, our purpose-built inference chip. Neuron plugs into popular ML frameworks like PyTorch and TensorFlow, and support for JAX is coming early next year. Customers like Adobe, Deutsche Telekom, and Leonardo.ai
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as data quality, algorithm, scalability, and domain knowledge, to mention a few. You can find more details about training datapreparation and understand the custom classifier metrics.
SageMaker Jumpstart is the machine learning (ML) hub of Amazon SageMaker , providing pre-trained, publicly available models for a wide range of problem types to help you get started with ML. SageMaker JumpStart solution templates SageMaker JumpStart provides one-click, end-to-end solutions for many common ML use cases.
This guarantees businesses can fully utilize deep learning in their AI and ML initiatives. You can make more informed judgments about your AI and ML initiatives if you know these platforms' features, applications, and use cases. Performance and Scalability Consider the platform's training speed and inference efficiency.
We use HyperbandStrategyConfig to configure StrategyConfig , which is later used by the tuning job definition. About the Author Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. In his spare time, he enjoys cycling, hiking, and complaining about datapreparation.
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed.
In this article, we will delve into the world of AutoML, exploring its definition, inner workings, and its potential to reshape the future of machine learning. It follows a comprehensive, step-by-step process: Data Preprocessing: AutoML tools simplify the datapreparation stage by handling missing values, outliers, and data normalization.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.
These statistics underscore the significant impact that Data Science and AI are having on our future, reshaping how we analyse data, make decisions, and interact with technology. AI encompasses various subfields, including Machine Learning (ML), Natural Language Processing (NLP), robotics, and computer vision.
We don’t claim this is a definitive analysis but rather a rough guide due to several factors: Job descriptions show lagging indicators of in-demand prompt engineering skills, especially when viewed over the course of 9 months. The definition of a particular job role is constantly in flux and varies from employer to employer.
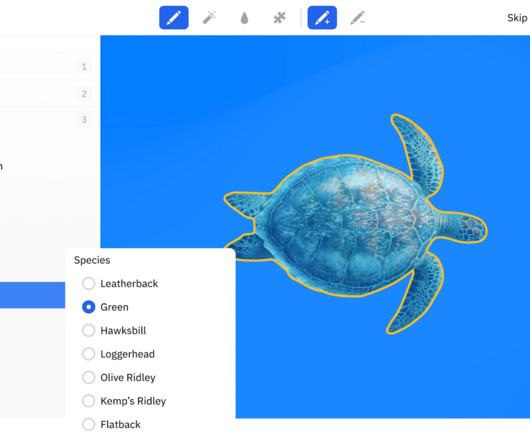
Image labeling and annotation are the foundational steps in accurately labeling the image data and developing machine learning (ML) models for the computer vision task. require image annotation so that ML models can interpret the images at a granular level and produce high-quality predictions in real-world applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content