This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recapping the Cloud Amplifier and Snowflake Demo The combined power of Snowflake and Domo’s Cloud Amplifier is the best-kept secret in data management right now — and we’re reaching new heights every day. If you missed our demo, we dive into the technical intricacies of architecting it below.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs. It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation.
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, preparedata for analytics and ML, and train ML models. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. Choose Continue.
Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. We will use this table to demo and test our custom functions.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
By bringing the unmatched AutoML capabilities of DataRobot to the data in Snowflake’s Data Cloud, customers get a seamless and comprehensive enterprise-grade data science platform.” They can enjoy a hosted experience with code snippets, versioning, and simple environment management for rapid AI experimentation.
This instance will be used for various tasks such as video processing and datapreparation. env_setup.cmd Prepare the sign video annotation file for each processing run: python prep_metadata.py Download the sign videos, segment them, and store them in Amazon S3: python create_sign_videos.py
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml For Prepare template , select Template is ready. Enter a stack name, such as Demo-Redshift. The environment preparation process may take some time to complete.
When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
It serializes these configuration dictionaries (or config dict for short) to their ProtoBuf representation, transports them to the client using gRPC, and then deserializes them back to Python dictionaries. Data is split into a training dataset and a testing dataset. Details of the datapreparation code are in the following notebook.
Often, to get an NLP application working for production use cases, we end up having to think about datapreparation and cleaning. This is covered with Haystack indexing pipelines , which allows you to design your own datapreparation steps, which ultimately write your documents to the database of your choice.
MLFlow From datapreparation through application deployment, MLFlow is an open-source platform that manages the whole machine learning lifecycle. Anomalib Anomalib is a Python library that helps users to detect anomalies in time-series data.
When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Book a demo today. Revamped Snorkel Flow SDK Also included in the 2023.R3 See what Snorkel option is right for you.
The spaCy configuration system The spaCy project system Final thoughts The spaCy configuration system If I were to redo my NER training project again, I’ll start by generating a config.cfg file: python -m spacy init config --pipeline ner config.cfg Think of config.cfg as our main hub, a complete manifest of our training procedure.
Solution overview In this solution, we start with datapreparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors.
Here is a quick demo of how it works Let's now dive deep into how I went about the project. Datapreparation The first thing I did was import the necessary libraries. I need to mount the data since the dataset is on my Google Drive. I made use of a separate Python script to perform this task. Sure, it does.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., It enables data scientists to log, compare, and visualize experiments, track code, hyperparameters, metrics, and outputs. and programmatically via the Kolena Python client.
This solution contains datapreparation and visualization functionality within SageMaker and allows you to train and optimize the hyperparameters of deep learning models for your dataset. You can use your own data or try the solution with a synthetic dataset as part of this solution. Finally, you launch SageMaker Studio.
My tips for working with code in notebooks are the following: Move auxiliary functions to plain Python modules Generally, importing functions defined in Python modules is better than defining them in the notebook. If a reviewer wants more detail, they can always look at the Python module directly. For one, Git diffs within.py
The latter will map the model’s outputs to final labels and significantly ease the datapreparation process. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Metaflow differs from other pipelining frameworks because it can load and store artifacts (such as data and models) as regular Python instance variables.
Gradio is an open-source Python library that helps you build easy-to-use demos for your ML model that you can share with other people. The ML lifecycle is an ongoing process from datapreparation to deployment and monitoring of the model. Let’s move on and have a look at what Gradio is.
Solution overview The chess demo uses a broad spectrum of AWS services to create an interactive and engaging gaming experience. The following architecture diagram illustrates the service integration and data flow in the demo. The demo offers a few gameplay options. Stockfish and chess Python libraries are GPL-3.0
The project uses Python and several open-source libraries, including LangChain, Chroma, and Gradio. DataPreparation The first step in building the RAG chatbot is to prepare the data. If youre interested in exploring this technology further, we encourage youto: Book a demo to see Arcee Conductor inaction.
Several activities are performed in this phase, such as creating the model, datapreparation, model training, evaluation, and model registration. Model lineage tracking captures and retains information about the stages of an ML workflow, from datapreparation and training to model registration and deployment.
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve. Choose Next.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. A prolific educator, Julien shares his knowledge through code demos, blogs, and YouTube, making complex AI accessible.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log dataPreparing your data to provide quality results is the first step in an AI project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















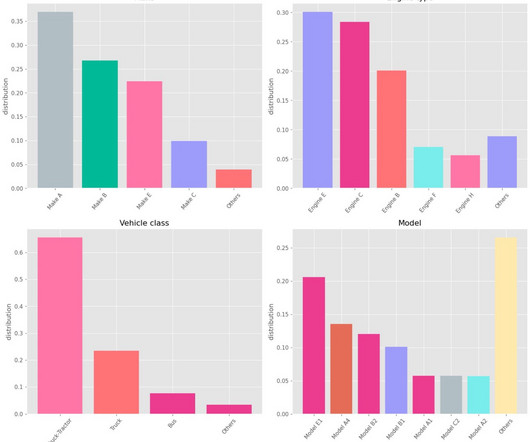














Let's personalize your content