This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This process is typically facilitated by document loaders, which provide a “load” method for accessing and loading documents into the memory. This involves splitting lengthy documents into smaller chunks that are compatible with the model and produce accurate and clear results.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
Generative AI (GenAI), specifically as it pertains to the public availability of large language models (LLMs), is a relatively new business tool, so it’s understandable that some might be skeptical of a technology that can generate professional documents or organize data instantly across multiple repositories.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. Each document is split page by page, with each page referencing the global in-memory PDFs.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
The significance of RAG is underscored by its ability to reduce hallucinationsinstances where AI generates incorrect or nonsensical informationby retrieving relevant documents from a vast corpora. Document Retrieval: The retriever processes the query and retrieves relevant documents from a pre-defined corpus.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. Search for the most relevant documents given the query “Fun animal toy” search("Fun animal toy", embeddings, docs) The following screenshots show the output. jpg") or doc.endswith(".png"))
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Dataset preparation for visual question and answering tasks The Meta Llama 3.2
With data software pushing the boundaries of what’s possible in order to answer business questions and alleviate operational bottlenecks, data-driven companies are curious how they can go “beyond the dashboard” to find the answers they are looking for. One of the standout features of Dataiku is its focus on collaboration.
Document understanding Fine-tuning is particularly effective for extracting structured information from document images. This includes tasks like form field extraction, table data retrieval, and identifying key elements in invoices, receipts, or technical diagrams. When working with documents, note that Meta Llama 3.2
Every day, businesses manage an extensive volume of documents—contracts, invoices, reports, and correspondence. Critical data, often in unstructured formats that can be challenging to extract, is embedded within these documents. So, how can we effectively extract information from documents?
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. This post dives into key steps for preparingdata to build real-world ML systems.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Comprehensive documentation and type hints – It provides robust and comprehensive documentation and type hints so developers can understand the functionalities of the APIs and objects, write code faster, and reduce errors. Datapreparation In this phase, prepare the training and test data for the LLM.
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
For more information see the prompt lab documentation. For more information see the tuning studio documentation. Data Science and MLOps: Tools, pipelines and runtimes that support building ML models automatically, and automate the full lifecycle from development to deployment. For more information see Prompt Lab documentation.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
This consistent documentation fosters trust and accountability, which are crucial as machine learning technology continues to evolve and integrate into diverse applications. An ML model card is a standardized document that offers detailed insights into machine learning models. What is an ML model card?
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. politics, sports) that a document belongs to.
We go through several steps, including datapreparation, model creation, model performance metric analysis, and optimizing inference based on our analysis. We also go through best practices and optimization techniques during datapreparation, model building, and model tuning. For Version , specify 1.
What they’re testing: Basic datapreparation awareness as it relates to visualization. Sample Answer: “First, I’d try to understand why the data is missing is it random, or is there a pattern? The approach depends on the context and the amount of missing data. How would you approach this?
This archive, along with 765,933 varied-quality inspection photographs, some over 15 years old, presented a significant data processing challenge. Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. EC2 Trn1 instances offer up to 52% cost-to-train savings compared to comparable EC2 instance types.
It details the necessary setup, datapreparation requirements, the step-by-step fine-tuning workflow, methods for leveraging the resulting custom models, and illustrative examples of potential use cases. This report provides a comprehensive technical guide to utilizing the Mistral AI Classifier Factory.
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. Initialize DocumentStore and index documents.
Here’s how we created the transactions table in Snowflake in our Jupyter Notebook: Next, we generated the Customers table: These snippets illustrate creating a new table in Snowflake and then inserting data from a Pandas DataFrame. You can visit Snowflake’s API Documentation for more detailed examples and documentation.
release includes features that speed up and streamline your datapreparation and analysis. Automate dashboard insights with Data Stories. If you've ever written an executive summary of a dashboard, you know it’s time consuming to distill the “so what” of the data. But, proper datapreparation pays off in dividends.
release includes features that speed up and streamline your datapreparation and analysis. Automate dashboard insights with Data Stories. If you've ever written an executive summary of a dashboard, you know it’s time consuming to distill the “so what” of the data. But, proper datapreparation pays off in dividends.
Tableau+ includes: Einstein Copilot for Tableau (only in Tableau+) : Get an intelligent assistant that helps make Tableau easier and analysts more efficient across the platform: In Tableau Prep (coming in 2024.2) : Automate formula creation and speed up datapreparation.
Extracting data from PDFs requires establishing rules and logic for each data element, a substantial effort worthwhile only for multiple PDFs with similar structures. However, when dealing with documents from thousands of vendors with varying formats that may change over time, developing mapping rules becomes an immense task.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
Another example is in the field of text document similarity. Imagine you have a vast library of documents and want to identify near-duplicate documents or find documents similar to a query document. Developed by Moses Charikar, SimHash is particularly effective for high-dimensional data (e.g.,
Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage. Because the data is being fetched hourly, a mechanism is also required to orchestrate and schedule ingestion jobs. Data comes from disparate sources in a number of formats.
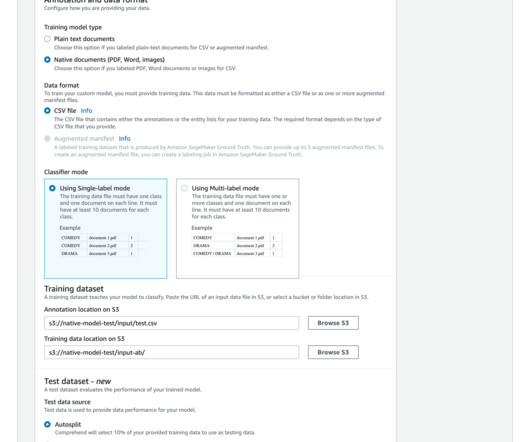
Amazon Comprehend is a managed AI service that uses natural language processing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
However, LLMs alone lack access to company-specific data, necessitating a retriever to fetch relevant information from various sources (databases, documents, etc.). It details the challenges of handling large documents and datasets and the importance of re-ranking retrieved information to ensure relevance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content