This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
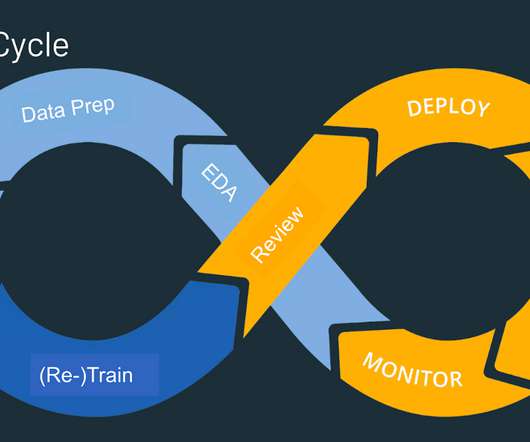
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes.
Datapreparation is a crucial step in any machinelearning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
Dataiku is an advanced analytics and machinelearning platform designed to democratize data science and foster collaboration across technical and non-technical teams. Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machinelearning models.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
Introduction Machinelearning models learn patterns from data and leverage the learning, captured in the model weights, to make predictions on new, unseen data. Data, is therefore, essential to the quality and performance of machinelearning models.
The ability to quickly build and deploy machinelearning (ML) models is becoming increasingly important in today’s data-driven world. From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete.
Customers increasingly want to use deep learning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machinelearning (ML) may contain personally identifiable information (PII).
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. Each document is split page by page, with each page referencing the global in-memory PDFs.
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machinelearning (ML) lifecycle. Datapreparation In this phase, prepare the training and test data for the LLM.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Dataset preparation for visual question and answering tasks The Meta Llama 3.2
Top 10 AI tools for data analysis AI Tools for Data Analysis 1. TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is used for machinelearning, natural language processing, and computer vision tasks.
The significance of RAG is underscored by its ability to reduce hallucinationsinstances where AI generates incorrect or nonsensical informationby retrieving relevant documents from a vast corpora. Document Retrieval: The retriever processes the query and retrieves relevant documents from a pre-defined corpus.
Amazon SageMaker is a comprehensive, fully managed machinelearning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. jpg") or doc.endswith(".png"))
MPII is using a machinelearning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
This year, generative AI and machinelearning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Hear from Availity on how 1.5
In what ways do we understand image annotations, the underlying technology behind AI and machinelearning (ML), and its importance in developing accurate and adequate AI training data for machinelearning models? Overall, it shows the more data you have, the better your AI and machinelearning models are.
Amazon Comprehend is a natural-language processing (NLP) service that uses machinelearning to uncover valuable insights and connections in text. Knowledge management – Categorizing documents in a systematic way helps to organize an organization’s knowledge base. They can search within specific categories to narrow down results.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Inability to learn: RPA cannot learn from past experiences or adapt to new situations without human intervention. What is machinelearning (ML)?
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. These stages are applicable to both use case and model stages. Madhubalasri B.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
Summary: Data quality is a fundamental aspect of MachineLearning. Poor-quality data leads to biased and unreliable models, while high-quality data enables accurate predictions and insights. What is Data Quality in MachineLearning? What is Data Quality in MachineLearning?
is a next-generation enterprise studio for AI builders, bringing new generative AI capabilities powered by foundation models , in addition to machinelearning capabilities. For more information see the prompt lab documentation. For more information see the tuning studio documentation. IBM® watsonx.ai The watsonx.ai
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion by 2031, growing at a CAGR of 34.20%.
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machinelearning. product specifications, movie metadata, documents, etc.)
Machinelearning operations (MLOps) are a set of practices that automate and simplify machinelearning (ML) workflows and deployments. The process begins with datapreparation, followed by model training and tuning, and then model deployment and management.
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of PyCaret} Image by Author In the rapidly evolving realm of data science, the imperative to automate machinelearning workflows has become an indispensable requisite for enterprises aiming to outpace their competitors.
Machinelearning has become an essential part of our lives because we interact with various applications of ML models, whether consciously or unconsciously. MachineLearning Operations (MLOps) are the aspects of ML that deal with the creation and advancement of these models.
Every day, businesses manage an extensive volume of documents—contracts, invoices, reports, and correspondence. Critical data, often in unstructured formats that can be challenging to extract, is embedded within these documents. So, how can we effectively extract information from documents?
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Also, check the frequency and stability of updates and improvements to the tool.
This post is co-authored by Anatoly Khomenko, MachineLearning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. The system is developed by a team of dedicated applied machinelearning (ML) scientists, ML engineers, and subject matter experts in collaboration between AWS and Talent.com.
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machinelearning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. The documentation lists the steps to migrate from SageMaker Studio Classic. Get started on SageMaker Studio here.
Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value. Solution overview Amazon SageMaker is a fully managed service that helps developers and data scientists build, train, and deploy machinelearning (ML) models.
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. This post dives into key steps for preparingdata to build real-world ML systems.
Artificial intelligence (AI) and machinelearning (ML) have seen widespread adoption across enterprise and government organizations. Processing unstructured data has become easier with the advancements in natural language processing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend.
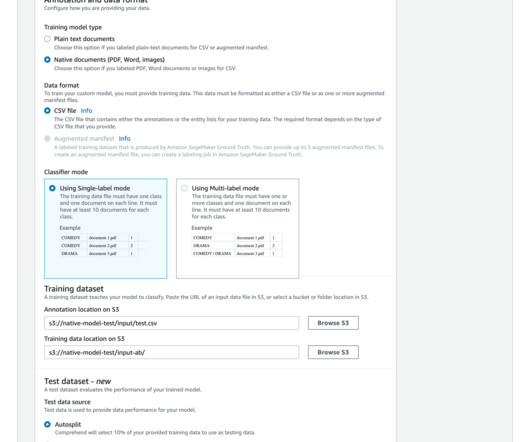
In simple terms, data annotation helps the algorithms distinguish between what's important and what's not with the help of labels and annotations, allowing them to make informed decisions and predictions. Now you might be wondering, why exactly we need these annotation tools when we can label the ML data on our own.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machinelearning (ML), retail, and data and analytics. The information and procedures in this section help you understand how to properly use the documentation provided by your IdP.
By using the Framework, you will learn current operational and architectural recommendations for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in AWS. By reading this post, you will learn about the Security Pillar in the Well-Architected Framework, and its application to the IDP solutions.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content