This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful dataprocessing capabilities of EMR Serverless. Each document is split page by page, with each page referencing the global in-memory PDFs.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering naturallanguage questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
Processing unstructured data has become easier with the advancements in naturallanguageprocessing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend. We will be using the Data-Preparation notebook. For Input format , choose One document per line.
Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Knowledge management – Categorizing documents in a systematic way helps to organize an organization’s knowledge base. politics, sports) that a document belongs to.
TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is used for machine learning, naturallanguageprocessing, and computer vision tasks.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. RPA and ML are two different technologies that serve different purposes.
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. Initialize DocumentStore and index documents.
An intelligent documentprocessing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific entities or phrases. You can either secure the output PII in your data store or redact the PII in your IDP output.
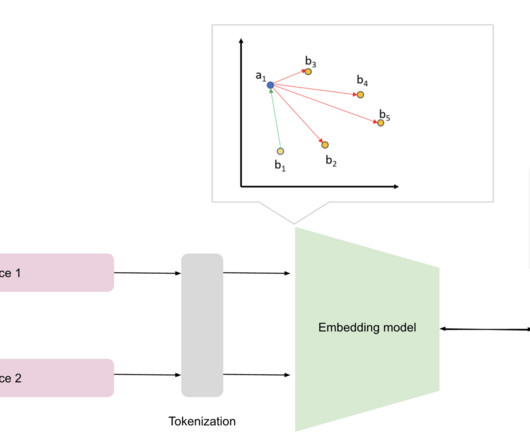
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art naturallanguageprocessing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. We enhance the embeddings through an SBERT model we fine-tuned.
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). Bag-of-Words representation The bag-of-words (BOW) representation is a widely used technique in sentiment analysis, where each document is represented as a set of words.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. Text classification is essential for applications like web searches, information retrieval, ranking, and document classification.
Amazon Comprehend is a managed AI service that uses naturallanguageprocessing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Due to various government regulations and rules, customers have to find a mechanism to handle this sensitive data with appropriate security measures to avoid regulatory fines, possible fraud, and defamation. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines.
Community Support and Documentation A strong community around the platform can be invaluable for troubleshooting issues, learning new techniques, and staying updated on the latest advancements. Assess the quality and comprehensiveness of the platform's documentation. It is well-suited for both research and production environments.
These commodity classes are associated with emission factors used to estimate environmental impacts using expenditure data. The Eora MRIO (Multi-region input-output) dataset is a globally recognized spend-based emission factor set that documents the inter-sectoral transfers amongst 15.909 sectors across 190 countries.
Gather data from various sources, such as Confluence documentation and PDF reports. The Fine-tuning Workflow with LangChain DataPreparation Customize your dataset to fine-tune an LLM for your specific task. Step 1: Organizing knowledge base Break down your knowledge base into smaller, manageable chunks.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Genomic language models Genomic language models represent a new approach in the field of genomics, offering a way to understand the language of DNA. Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of naturallanguageprocessing, modeling, data analysis, data cleaning, and data visualization.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using naturallanguageprocessing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. RPA and ML are two different technologies that serve different purposes.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Table of Contents Introduction to PyCaret Benefits of PyCaret Installation and Setup DataPreparation Model Training and Selection Hyperparameter Tuning Model Evaluation and Analysis Model Deployment and MLOps Working with Time Series Data Conclusion 1. or higher and a stable internet connection for the installation process.
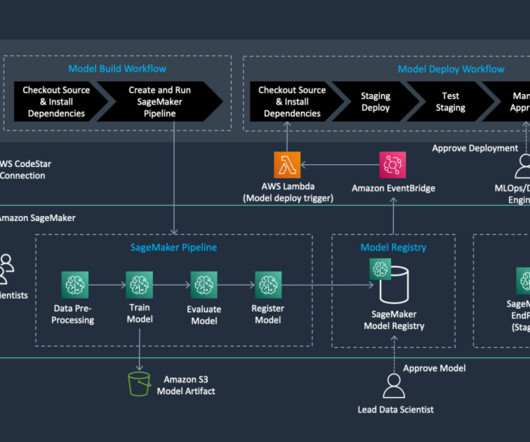
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. This ensures that your ML code base and pipelines are versioned, documented, and accessible by team members.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. Naturally occurring text may contain biases, inaccuracies, grammatical errors, and syntax variations.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Check out the Kubeflow documentation. It provides a high-level API that makes it easy to define and execute data science workflows.
These development platforms support collaboration between data science and engineering teams, which decreases costs by reducing redundant efforts and automating routine tasks, such as data duplication or extraction. AutoAI automates datapreparation, model development, feature engineering and hyperparameter optimization.
They have deep end-to-end ML and naturallanguageprocessing (NLP) expertise and data science skills, and massive data labeler and editor teams. Models with larger context windows can understand and generate longer sequences of text, which can be useful for tasks involving longer conversations or documents.
Documented : Good model packaging includes clear code documentation that helps others understand how to use and modify the model if required. Collaboration should start early in the model packaging process, and all teams should be involved in the design and development stages of the project.
Objects in an image can be labeled, boundaries can be identified, and metadata can be generated using image annotation, which is part of the datapreparationprocess for AI and machine learning tasks. Annotating images also helps improve facial recognition algorithms and allows robots to be trained to perform tasks.
Introduction Large language models (LLMs) such as GPT-3.5 These models empower us to enhance creativity , reasoning , and understanding across various domains , enabling tasks such as summarizing text , analyzing documents , generating code , and crafting contextually relevant responses. But how do they do it? So, let’s get started!
These networks can learn from large volumes of data and are particularly effective in handling tasks such as image recognition and naturallanguageprocessing. Key Deep Learning models include: Convolutional Neural Networks (CNNs) CNNs are designed to process structured grid data, such as images.
With CL, you can ensure that the model learns from the latest data and adapts to it as effectively and quickly as possible. With continual learning, you can use each document to automatically retrain models, gradually adjusting it to the data the user uploads to the system. In such a case, we cannot use a memory buffer.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content