This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. You can download the dataset loans-part-1.csv
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Choose the method that suits your needs and use case.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
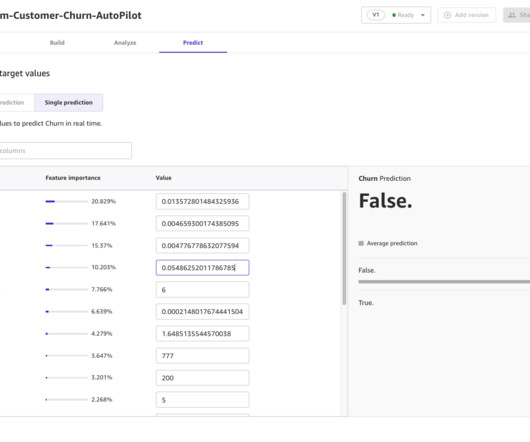
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. You can now view the predictions and download them as CSV.
It offers industry-leading scalability, data availability, security, and performance. SageMaker Canvas now supports comprehensive datapreparation capabilities powered by SageMaker Data Wrangler. We also demonstrate using the chat for data prep feature in SageMaker Canvas to analyze the data and visualize your findings.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. For Prepare template , select Template is ready. Enter a stack name, such as Demo-Redshift.
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. script to download the model and tokenizer. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Machine learning (ML) helps organizations generate revenue, reduce costs, mitigate risk, drive efficiencies, and improve quality by optimizing core business functions across multiple business units such as marketing, manufacturing, operations, sales, finance, and customer service. On the Studio console, choose AutoML in the navigation pane.
The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. This is where the AWS suite of low-code and no-code ML services becomes an essential tool.
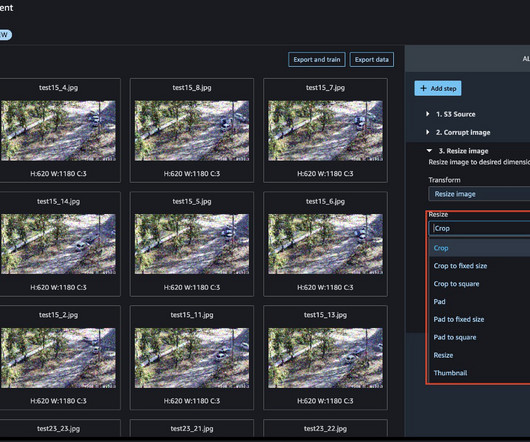
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import.
Let’s get started with the best machine learning (ML) developer tools: TensorFlow TensorFlow, developed by the Google Brain team, is one of the most utilized machine learning tools in the industry. Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis.
Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. SageMaker Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity.
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. jpg") or doc.endswith(".png"))
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
Artificial intelligence (AI) and machine learning (ML) have seen widespread adoption across enterprise and government organizations. Processing unstructured data has become easier with the advancements in natural language processing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend.
Customers increasingly want to use deep learning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII).
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
On November 30, 2021, we announced the general availability of Amazon SageMaker Canvas , a visual point-and-click interface that enables business analysts to generate highly accurate machine learning (ML) predictions without having to write a single line of code. The key to scaling the use of ML is making it more accessible.
Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. For more information, refer to Granting Data Catalog permissions using the named resource method. We have completed the datapreparation step.
You can use machine learning (ML) to generate these insights and build predictive models. Educators can also use ML to identify challenges in learning outcomes, increase success and retention among students, and broaden the reach and impact of online learning content. Download the following student dataset to your local computer.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. We start from creating a data flow. To learn more about importing data to SageMaker Canvas, see Import data into Canvas.
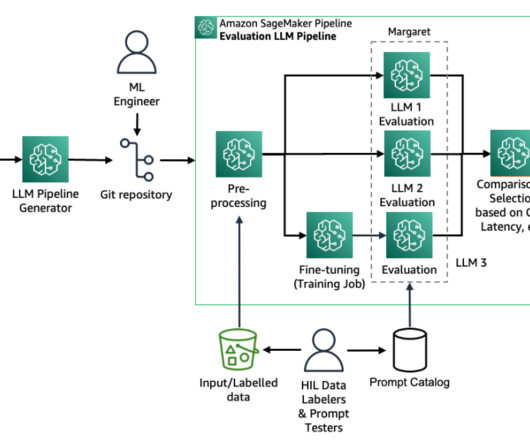
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. Solution overview Running hundreds of experiments, comparing the results, and keeping a track of the ML lifecycle can become very complex. In the preproccess step, you can log training data and evaluation data.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference data pipeline on large datasets is a challenge many companies face. SageMaker Batch Job Allows you to run batch inference on large datasets and generate predictions in a batch mode using machine learning (ML) models hosted in SageMaker.
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. Benefits of SageMaker Canvas Forecast customers have been seeking greater transparency, lower costs, faster training, and enhanced controls for building time series ML models.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Data scientist experience In this section, we cover how data scientists can connect to Snowflake as a data source in Data Wrangler and preparedata for ML.
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, ML engineers, and application developers to harness the full potential of FMs while addressing unique application requirements. SageMaker Studio is a single web-based interface for end-to-end machine learning (ML) development.
Amazon SageMaker Canvas is a rich, no-code Machine Learning (ML) and Generative AI workspace that has allowed customers all over the world to more easily adopt ML technologies to solve old and new challenges thanks to its visual, no-code interface. For example, using the AWS SDK for Python ( boto3 ): import boto3, datetime cw = boto3.client('cloudwatch')
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
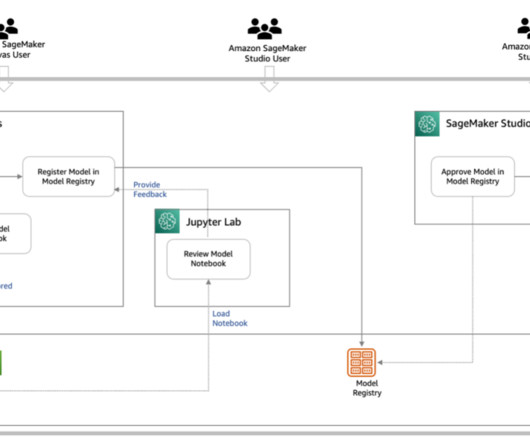
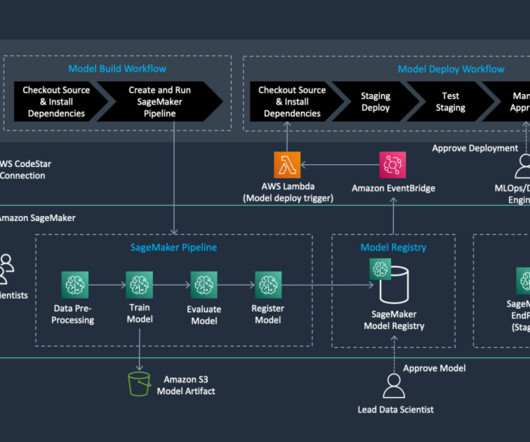
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
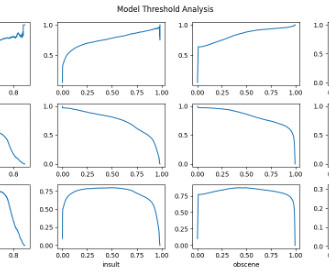
Since its introduction, we’ve helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage. In this post, we focus on data preprocessing using Amazon SageMaker Processing and Amazon SageMaker Data Wrangler jobs.
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket.
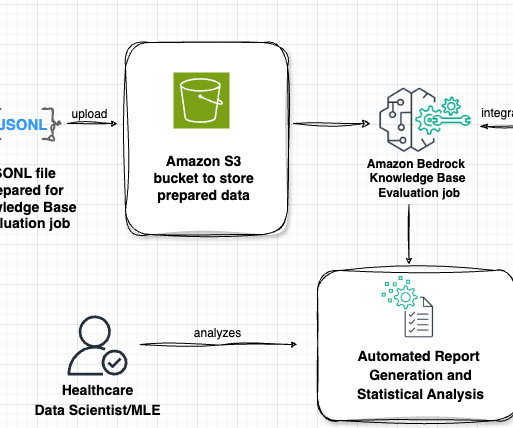
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
Users can input audio, video, or text into GenASL, which generates an ASL avatar video that interprets the provided data. The solution uses AWS AI and machine learning (AI/ML) services, including Amazon Transcribe , Amazon SageMaker , Amazon Bedrock , and FMs. You can download and install Docker from Docker’s official website.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
Prepare the dataset for fine-tuning We use the low-resource language Marathi for the fine-tuning task. Using the Hugging Face datasets library, you can download and split the Common Voice dataset into training and testing datasets. His current areas of focus are AI/ML infrastructure and applications.
Recently, the standard GNN has been combined with ideas from other ML models to develop exciting, innovative applications. One such development is the integration of GNN with sequential models — Spatio-Temporal GNN that is able to capture both the temporal and spatial (hence the name) dependences of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content