This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The workflow adapts automatically to any CSV structure, allowing you to quickly assess multiple datasets and prioritize your datapreparation efforts. This transforms your workflow into a distribution system where quality reports are automatically sent to project managers, data engineers, or clients whenever you analyze a new dataset.
In this post, we explore how SageMaker Canvas and SageMaker Data Wrangler provide no-code datapreparation techniques that empower users of all backgrounds to preparedata and build time series forecasting models in a single interface with confidence. SageMaker Canvas has various offerings to accomplish this.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and data scientists face significant challenges customizing these large models. Download the SQuaD dataset and upload it to SageMaker Lakehouse by following the steps in Uploading data.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring.
Processing unstructured data has become easier with the advancements in naturallanguageprocessing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend. We will be using the Data-Preparation notebook. On the New menu, choose Terminal.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Prepare the data for the model.
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. These tools are becoming increasingly sophisticated, enabling the development of advanced applications.
Solution overview This solution uses Amazon Comprehend and SageMaker Data Wrangler to automatically redact PII data from a sample dataset. Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required.
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. This is where MLflow can help streamline the ML lifecycle, from datapreparation to model deployment.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
You can watch the full video of this session here and download the slideshere. Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. For instance: DataPreparation: GoogleSheets.
Genomic language models Genomic language models represent a new approach in the field of genomics, offering a way to understand the language of DNA. We use a SageMaker notebook to process the genomic files and to import these into a HealthOmics sequence store. These weights are pretrained on the human reference genome.
With the addition of forecasting, you can now access end-to-end ML capabilities for a broad set of model types—including regression, multi-class classification, computer vision (CV), naturallanguageprocessing (NLP), and generative artificial intelligence (AI)—within the unified user-friendly platform of SageMaker Canvas.
Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. Data Curation in LLaVA Datapreparation in LLaVA is a three-tiered process: Conversational Data: Curating dialogues for interaction-focused tasks. Kudriavtsev, eds., Join the Newsletter!
The advancement of LLMs has significantly impacted naturallanguageprocessing (NLP)-based SQL generation, allowing for the creation of precise SQL queries from naturallanguage descriptions—a technique referred to as Text-to-SQL. The model weights will be stored in your local machine’s cache.
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Download the template.yml file to your computer. Upload the template you downloaded. Choose Create a new portfolio. Choose Review.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using naturallanguageprocessing (NLP) and advanced search algorithms. For more information, refer to Granting Data Catalog permissions using the named resource method.
They have deep end-to-end ML and naturallanguageprocessing (NLP) expertise and data science skills, and massive data labeler and editor teams. Open-source models are (in general) always fine-tunable because the model artifacts are available for downloading and the users are able to extend and use them at will.
The architecture incorporates best practices in MLOps, making sure that the different stages of the ML lifecyclefrom datapreparation to production deploymentare optimized for performance and reliability. This new design accelerates model development and deployment, so Radial can respond faster to evolving fraud detection challenges.
Amazon Comprehend is a managed AI service that uses naturallanguageprocessing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. Naturally occurring text may contain biases, inaccuracies, grammatical errors, and syntax variations.
We will be using GIST-large-Embedding-v0 from Aivin Solatorio that we will fine-tune on synthetic data generated by LLM called “ zephyr-7b-beta ” which is a fine-tuned version of the Mistral-7B-v0.1. Specifically, we will be looking into how to fine-tune an embedding model for retrieving relevant data and queries.
MLOps is a set of principles and practices that combine software engineering, data science, and DevOps to ensure that ML models are deployed and managed effectively in production. MLOps encompasses the entire ML lifecycle, from datapreparation to model deployment and monitoring. Why Is MLOps Important? How Does MLOps Work?
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
Sales teams can forecast trends, optimize lead scoring, and enhance customer engagement all while reducing manual data analysis. IBM Watson A pioneer in AI-driven analytics, IBM Watson transforms enterprise operations with naturallanguageprocessing, machine learning, and predictive modeling.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





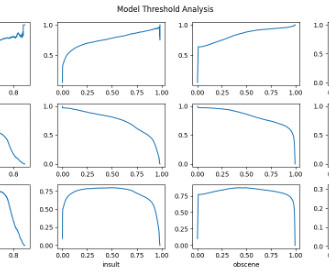



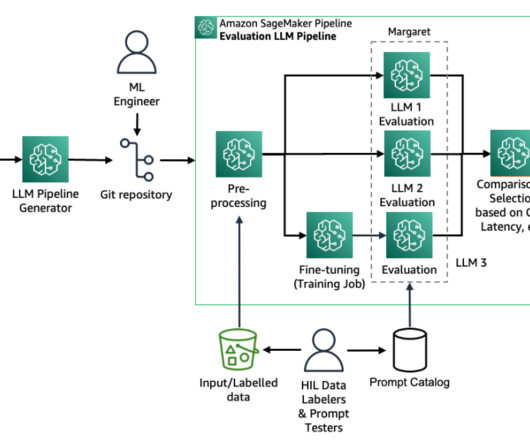






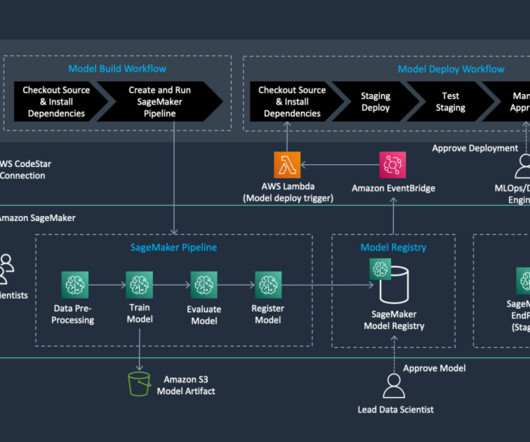






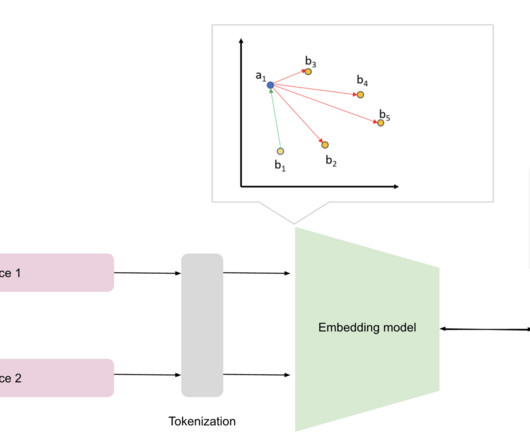










Let's personalize your content