This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. The following is the bash script for the Python environment setup. get_model.sh.
In such situations, it may be desirable to have the data accessible to SageMaker in the ephemeral storage media attached to the ephemeral training instances without the intermediate storage of data in Amazon S3. We add this data to Snowflake as a new table. Launch a SageMaker Training job for training the ML model.
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Define a Dockerfile.
You can use SageMaker Data Wrangler to simplify and streamline dataset preprocessing and feature engineering by either using built-in, no-code transformations or customizing with your own Python scripts. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines. Add a destination node.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. Finally, we deploy the ONNX model along with a custom inference code written in Python to Azure Functions using the Azure CLI. image and Python 3.0
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. Vision models. You can access the Meta Llama 3.2
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket.
DataPreparation Here we use a subset of the ImageNet dataset (100 classes). You can follow command below to download the data. Create a Milvus collection Define a schema for your collection in Milvus, specifying data types for image IDs and feature vectors (usually floats). Building the Image Search Pipeline 1.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
You can download and install Docker from Docker’s official website. This instance will be used for various tasks such as video processing and datapreparation. For instructions to install FFmpeg on the Windows EC2 instance, refer to Download FFmpeg. Generate avatar videos: python create_pose_videos.py
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
This is where MLflow can help streamline the ML lifecycle, from datapreparation to model deployment. You can create workflows with SageMaker Pipelines that enable you to preparedata, fine-tune models, and evaluate model performance with simple Python code for each step.
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, preparedata for analytics and ML, and train ML models. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
Its seamless integration capabilities make it highly compatible with numerous other Python libraries, which is why Scikit Learn is favored by many in the field for tackling sophisticated machine learning problems. PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
Download it here and support a fellow community member. Python = Powerful AI Research Agent By Gao Dalie () This article details building a powerful AI research agent using Pydantic AI, a web scraper (Tavily), and Llama 3.3. If you have any questions or feedback, write it in the thread! AI poll of the week! Meme of the week!
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code.
Prepare the dataset for fine-tuning We use the low-resource language Marathi for the fine-tuning task. Using the Hugging Face datasets library, you can download and split the Common Voice dataset into training and testing datasets. The source code associated with this implementation can be found on GitHub.
SageMaker Canvas simplifies your datapreparation with automated solutions for filling in missing values, making your forecasting efforts as seamless as possible. Python script – Use a Python script to merge the datasets.
Meta Llama3 8B is a gated model on Hugging Face, which means that users must be granted access before they’re allowed to download and customize the model. QLoRA quantizes a pretrained language model to 4 bits and attaches smaller low-rank adapters (LoRA), which are fine-tuned with our training data.
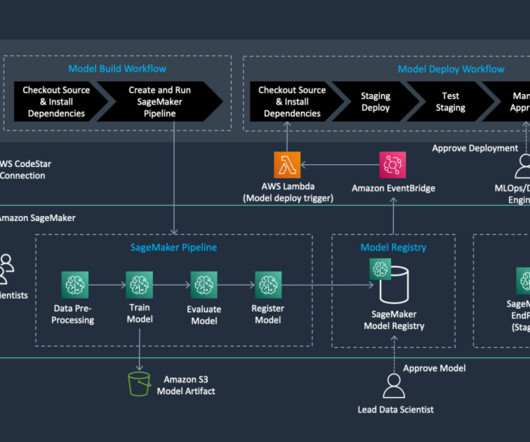
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Download the template.yml file to your computer. Upload the template you downloaded. Choose Create a new portfolio. Choose Review.
For Prepare template , select Template is ready. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select.
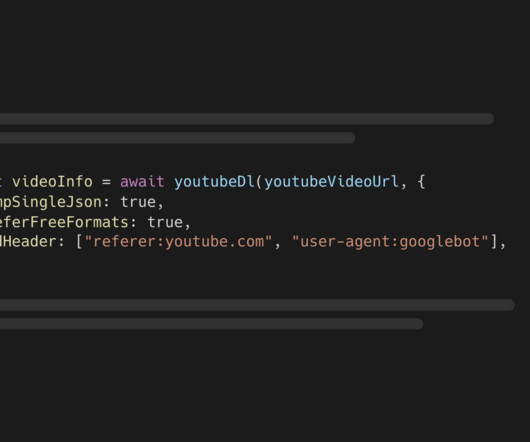
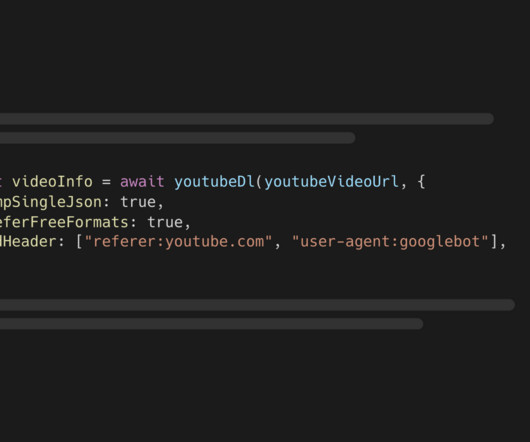
youtube-dl-exec wraps the yt-dlp CLI tool which lets you retrieve information about YouTube videos and download them. tsx lets you execute TypeScript code without additional setup npm install --save assemblyai youtube-dl-exec tsx You must also install Python 3.7 Python skills are essential. Come back later to fill gaps.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
Tweets inference data pipeline architecture Tweets Inference Data Pipeline Architecture (Screenshot by Author) The workflow performs the following tasks: Download Tweets Dataset: Download the tweets dataset from the S3 bucket. In this blog post, we will install Apache-Airflow using the Python package.
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
You can download the endzone and sideline videos , and also the ground truth labels. We use OpenCV for reading, writing, and manipulating image data in Python. In particular, we focus on deduplicating and visualizing videos with the ID 57583_000082 in endzone and sideline views. astype('str') + '_' + df['playID'].astype('str').str.zfill(6)
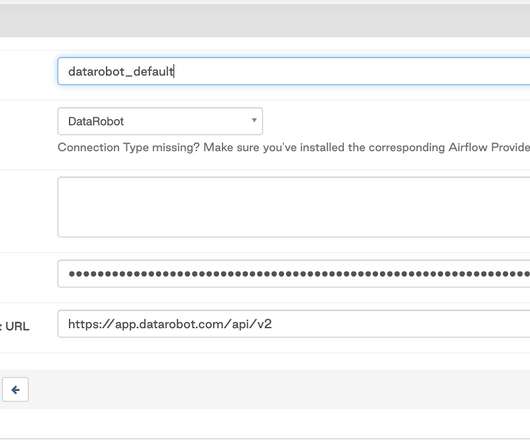
The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index). The integration uses the DataRobot Python API Client , which communicates with DataRobot instances via REST API. DataRobot Python API Client >= 2.27.1.
youtube-dl-exec wraps the yt-dlp CLI tool which lets you retrieve information about YouTube videos and download them. tsx lets you execute TypeScript code without additional setup npm install --save assemblyai youtube-dl-exec tsx You must also install Python 3.7 Python skills are essential. Come back later to fill gaps.
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
A guide to train YoloV7 model on custom dataset using Python Source:Author Introduction Deep Learning (DL) technologies are now being widely adopted by different organizations that want to improve their services in no time along with great accuracy. For the image annotation, you can use the LabelImg tool , while Python 3.9
Competition runtime limits ¶ Before preparing your submission, please ensure you understand the runtime environment and its constraints: Your submission must run using Python 3.12 The official runtime replaces this with the actual test data. Prepare your submission : Save all submission files (e.g.,
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data.
In this blog, we will focus on integrating Power BI within KNIME for enhanced data analytics. KNIME and Power BI: The Power of Integration The data analytics process invariably involves a crucial phase: datapreparation. This phase demands meticulous customization to optimize data for analysis.
I downloaded 50 samples from each, but something unfortunate happened — all the images I collected got deleted! I also had to make sure that I downloaded only good photos of the different textiles I was interested in. I also had to make sure that I downloaded only good photos of the different textiles I was interested in.
Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. For more information, refer to Granting Data Catalog permissions using the named resource method. We have completed the datapreparation step.
Users can download datasets in formats like CSV and ARFF. How to Access and Use Datasets from the UCI Repository The UCI Machine Learning Repository offers easy access to hundreds of datasets, making it an invaluable resource for data scientists, Machine Learning practitioners, and researchers. CSV, ARFF) to begin the download.
Check one of my previous stories if you want to learn how to use YOLOv5 with Python or C++. In this story, we will not use one of those high performing off-the-shelf object detectors but develop a new one ourselves, from scratch, using plain python, OpenCV, and Tensorflow. This is basically the path in which we are going to walk here.
Prerequisites To follow along with this tutorial, make sure you: Use a Google Colab Notebook to follow along Install these Python packages using pip: CometML , PyTorch, TorchVision, Torchmetrics and Numpy, Kaggle %pip install - upgrade comet_ml>=3.10.0 !pip To download it, you will use the Kaggle package.
Alteryx provides organizations with an opportunity to automate access to data, analytics , data science, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and data science.
Solution overview In this solution, we start with datapreparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., The entire model can be downloaded to your source code’s runtime with a single line of code. and programmatically via the Kolena Python client.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content